はじめに
Oculus Rift を使用して、VR 内のキャラと目が合う、握手できるなどの衝撃体験を @GOROman さんが実現されて話題になっています。
- Dive into VR - Oculus Rift + Razer Hydra feat. Miku - YouTube
- Oculus Rift で 初音ミク と握手をしてみた - Miku Miku Akushu - YouTube
そこで、VR の世界をもっと面白くする次のステップとしてVR キャラと会話をする、というところに挑戦したいと考えています。音声合成と AI 部分は、まずは以前も作成した OpenJTalk + SimSimi API などでやろうと思っています*1。
が、当時やった際は1つ重要な要素が抜けていました。リップシンクです。最近は Unity と MMD4U や MMD4M という素晴らしい環境があるため、これら使用すれば 3D キャラ側の口を動かすことはそんなに難しくないように思われます。しかしながら、声に合わせて動かすには音声を解析して口の形を与える必要があります。個人で開発されている先行事例としては SHYNCROiD の開発者なヲタさんが、「リップシンクロイド」というリアルタイムにリップシンクを行うシステムを作られていました。
なヲタさんは自作されているようです(Max/MSP 使用?)。ネットを探してみても、あまりリップシンク関連のライブラリはないように感じます。そこで、知り合いの音関係に詳しい方に尋ねたところ、「フォルマントを見れば母音なら分かるんじゃない?」というお話だったので、まずはフォルマントを解析して母音をリアルタイムに解析して見るところを作成してみました。
ただ前提として、音声信号処理はからっきしの専門外の人間なので色々と誤っている点があると思いますがご了承下さい。
(2013/12/27 追記:リップシンク出来ました)
デモ
音量が大きいので注意して下さい。
フォルマントからの母音抽出手順
- フォルマント - Wikipedia
- フリーソフトでつくる音声認識システム: パターン認識・機械学習の初歩から対話システムまで - 荒木雅弘 - Google ブックス
- 線形予測分析(LPC) - 人工知能に関する断創録
音声の周波数スペクトルの第1ピーク と第2ピーク
の 2 つのベクトルの相関から、母音を割り出すことが出来るようです。手順は色々あるようですが、私は「人工知能に関する断創録」にて紹介されていた以下の形で解くことにしました。
- 微小時間音声データ取り込み(WAV ファイル or Mic)
- ハミング窓を掛けて周期波形にする(周波数高域ノイズ低減)
- レビンソン・ダービン法で LPC(線形予測分析)係数を得る
- 得られた係数を元にしたデジタルフィルタの周波数応答を得る
- これが LPC スペクトル包絡線
- 包絡線の山から1番目と2番目のフォルマント(
、
)を特定
離散的な音声データを FFT するだけでは得られる周波数データも離散的なデータになってしまいます(サンプリングを無限大にすれば連続)。そこで LPC 分析という手法を使用します。手法については素晴らしい解説があるので、詳しくは上記サイトさまをご覧ください。
一番ハマったのは、LPC スペクトル包絡線を得るところです。参考サイトでは python ベースで書かれており、信号処理用の scipy.signal というモジュールの scipy.signal.freqz といというデジタルフィルタの関数で LPC 係数からスペクトル包絡を求めていました。この部分がブラックボックスで分からず、なかなか所望の結果が得られませんでした*2。そこで、色々とググっていたところ、この freqz の実装を見つけました。
このおかげで何とかスペクトル包絡を得ることが出来ました。
環境
使用したライブラリ
- libsndfile
- WAV ファイルの取り込み
- fftw3
- portaudio
- マイクからの音声取り込み
コード
まずは wav ファイルベースで解析をしてみました。数値計算用に書いたのでコードが縦に長くてグダグダですがご了承下さい。
#include <fstream> #include <cstdio> #include <string> #include <memory> #include <complex> #include <vector> #include <cmath> #include <sndfile.h> #include <fftw3.h> #include <boost/format.hpp> using std::complex; using std::vector; using std::pair; // LPC 係数の次数 const int LPC_ORDER = 64; // 解析に用いる微小区間 (sec) const double WINDOW_DURATION = 0.04; // FFT する vector<double> fft(const vector<double>& input); // LPC スペクトル包絡を得る vector<double> lpc(const vector<double>& input, int order, double df); // [1 : -1] に正規化 vector<double> normalize(const vector<double>& input); // ハミング窓をかける vector<double> hamming(const vector<double>& input); // デジタルフィルタ vector<double> freqz(const vector<double>& b, const vector<double>& a, double df, int N); // フォルマント f1 / f2 を返す pair<double, double> formant(const vector<double>& input, double df); // フォルマントから母音を推定する std::string vowel(double f1, double f2); // 与えられた範囲の音の平均 double volume(const vector<double>& input); int main() { // 音声ファイル読み込み SF_INFO sinfo; std::shared_ptr<SNDFILE> sf( sf_open("aiueo.wav", SFM_READ, &sinfo), [](SNDFILE* ptr) { sf_close(ptr); }); const int frame = sinfo.frames; std::unique_ptr<short[]> input(new short[frame]); const double sample_rate = sinfo.samplerate; const double dt = 1.0 / sample_rate; sf_read_short(sf.get(), input.get(), frame); // 結果吐き出し用ファイル std::ofstream input_log("data.txt"); std::ofstream wav_log("wav.txt"); std::ofstream freq_log("freq.txt"); std::ofstream formant_log("formant.txt"); // 元音声データ書き出し for (int i = 0; i < frame; ++i) { input_log << boost::format("%1%\t%2%\n") % (dt * i) % input[i]; } // 微小音声区間取り出し const int window_size = static_cast<int>(WINDOW_DURATION / dt); const double df = 1.0 / (window_size / sample_rate); for (int n = 0; n < frame / window_size; ++n) { vector<double> data; for (int i = window_size * n; i < window_size * (n + 1) && i < frame; ++i) { data.push_back(input[i]); } auto hamming_result = normalize( hamming(data) ); auto lpc_result = normalize( lpc(hamming_result, LPC_ORDER, df) ); auto fft_result = normalize( fft(hamming_result) ); // 波形をファイルに書き出し // wav_log << "#data" << n << std::endl; // for (int i = 0; i < window_size; ++i) { // wav_log << boost::format("%1%\t%2%\t%3%\t%4%\n") // % (dt * i) % (data[i]) % (hamming_result[i]) % (lpc_result[i]); // } // wav_log << "\n" << std::endl; // 周波数特性をファイルに書き出し freq_log << "#data" << n << std::endl; for (int i = 0; i < window_size; ++i) { freq_log << boost::format("%1%\t%2%\t%3%\n") % (df * i) % (fft_result[i]) % (lpc_result[i]); } freq_log << "\n" << std::endl; // 得られた LPC スペクトル包絡線からフォルマントを抽出 auto formant_result = formant(lpc_result, df); double f1 = formant_result.first; double f2 = formant_result.second; formant_log << boost::format("%1%\t%2%\t%3%\n") % (dt * window_size * n) % f1 % f2; if (volume(data) < 1e4) { std::cout << "-"; } else { std::cout << boost::format("%1% (f1:%2%, f2:%3%)") % vowel(f1, f2) % f1 % f2; } std::cout << std::endl; } // Gnuplot で結果を確認 std::shared_ptr<FILE> freq_graph( popen("gnuplot -persist", "w"), [](FILE* ptr) { pclose(ptr); }); fprintf(freq_graph.get(), "load 'freq.plt'\n"); // std::shared_ptr<FILE> wav_graph( // popen("gnuplot -persist", "w"), [](FILE* ptr) { pclose(ptr); }); // fprintf(wav_graph.get(), "load 'wav.plt'\n"); return 0; } // FFT vector<double> fft(const vector<double>& input) { const int frame = input.size(); vector<complex<double>> in(frame), out(frame); auto plan = fftw_plan_dft_1d( frame, reinterpret_cast<fftw_complex*>(&in[0]), reinterpret_cast<fftw_complex*>(&out[0]), FFTW_FORWARD, FFTW_ESTIMATE ); for (int i = 0; i < frame; ++i) { in[i] = complex<double>(input[i], 0.0); } fftw_execute(plan); vector<double> fft_result(frame); for (int i = 0; i < frame; ++i) { fft_result[i] = abs(out[i]); } return fft_result; } // LPC vector<double> lpc(const vector<double>& input, int order, double df) { const int N = input.size(); // 自己相関関数 vector<double> r(N); const int lags_num = order + 1; for (int l = 0; l < lags_num; ++l) { r[l] = 0.0; for (int n = 0; n < N - l; ++n) { r[l] += input[n] * input[n + l]; } } // Levinson-Durbin のアルゴリズムで LPC 係数を計算 vector<double> a(order + 1, 0.0), e(order + 1, 0.0); a[0] = e[0] = 1.0; a[1] = - r[1] / r[0]; e[1] = r[0] + r[1] * a[1]; for (int k = 1; k < order; ++k) { double lambda = 0.0; for (int j = 0; j < k + 1; ++j) { lambda -= a[j] * r[k + 1 - j]; } lambda /= e[k]; vector<double> U(k + 2), V(k + 2); U[0] = 1.0; V[0] = 0.0; for (int i = 1; i < k + 1; ++i) { U[i] = a[i]; V[k + 1 - i] = a[i]; } U[k + 1] = 0.0; V[k + 1] = 1.0; for (int i = 0; i < k + 2; ++i) { a[i] = U[i] + lambda * V[i]; } e[k + 1] = e[k] * (1.0 - lambda * lambda); } // LPC 係数から音声信号再現 // vector<double> lpc_result(N, 0.0); // for (int i = 0; i < N; ++i) { // if (i < order) { // lpc_result[i] = input[i]; // } else { // for (int j = 1; j < order; ++j) { // lpc_result[i] -= a[j] * input[i + 1 - j]; // } // } // } // return lpc_result; return freqz(e, a, df, N); } // 正規化 vector<double> normalize(const vector<double>& input) { // 最大 / 最小値 auto max = abs( *std::max_element(input.begin(), input.end()) ); auto min = abs( *std::min_element(input.begin(), input.end()) ); double factor = std::max(max, min); vector<double> result( input.size() ); std::transform(input.begin(), input.end(), result.begin(), [factor](double x) { return x / factor; }); return result; } // ハミング窓をかける vector<double> hamming(const vector<double>& input) { const double N = input.size(); vector<double> result(N); for (int i = 1; i < N - 1; ++i) { const double h = 0.54 - 0.46 * cos(2 * M_PI * i / (N - 1)); result[i] = input[i] * h; } result[0] = result[N - 1] = 0; return result; } // デジタルフィルタ vector<double> freqz(const vector<double>& b, const vector<double>& a, double df, int N) { vector<double> H(N); for (int n = 0; n < N + 1; ++n) { auto z = std::exp(complex<double>(0.0, -2.0 * M_PI * n / N)); complex<double> numerator(0.0, 0.0), denominator(0.0, 0.0); for (int i = 0; i < b.size(); ++i) { numerator += b[b.size() - 1 - i] * pow(z, i); } for (int i = 0; i < a.size(); ++i) { denominator += a[a.size() - 1 - i] * pow(z, i); } H[n] = abs(numerator / denominator); } return H; } // フォルマント f1 / f2 を返す pair<double, double> formant(const vector<double>& input, double df) { pair<double, double> result(0.0, 0.0); bool is_find_first = false; for (int i = 1; i < input.size() - 1; ++i) { if (input[i] > input[i-1] && input[i] > input[i+1]) { if (!is_find_first) { result.first = df * i; is_find_first = true; } else { result.second = df * i; break; } } } return result; } // 母音を推定 // NOTE: 機械学習にする予定 std::string vowel(double f1, double f2) { if (f1 > 600 && f1 < 1400 && f2 > 900 && f2 < 2000) return "あ"; if (f1 > 100 && f1 < 410 && f2 > 1900 && f2 < 3500) return "い"; if (f1 > 100 && f1 < 700 && f2 > 1100 && f2 < 2000) return "う"; if (f1 > 400 && f1 < 800 && f2 > 1700 && f2 < 3000) return "え"; if (f1 > 300 && f1 < 900 && f2 > 500 && f2 < 1300) return "お"; return "-"; } // ボリューム double volume(const vector<double>& input) { double v = 0.0; std::for_each(input.begin(), input.end(), [&v](double x) { v += x*x; }); v /= input.size(); return v; }
ここに「あいうえお」と喋った wav を食わせてみました。
FFT したものと LPC スペクトル包絡(次数は 64)のグラフが以下になります。
あ
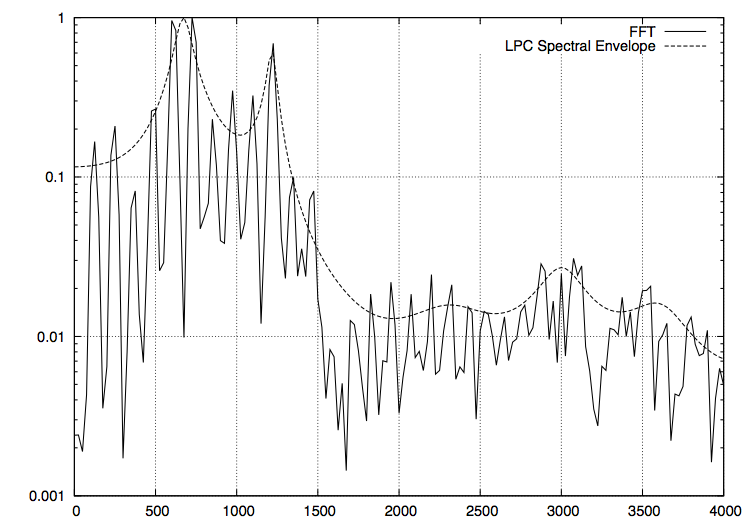
い
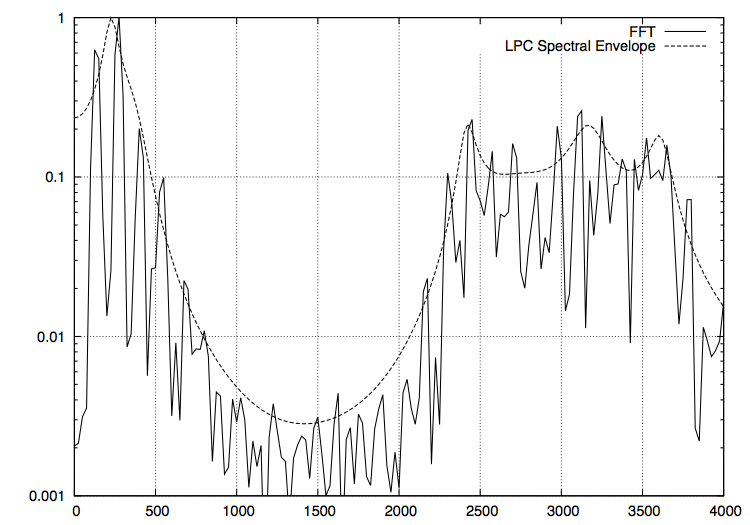
う
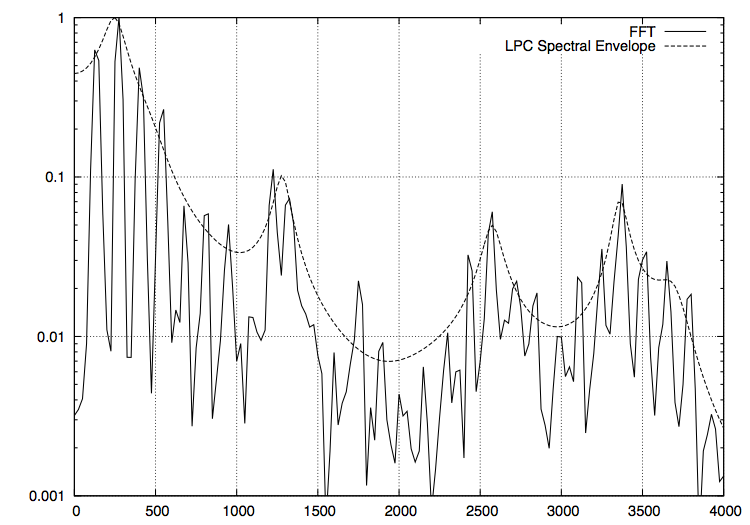
え
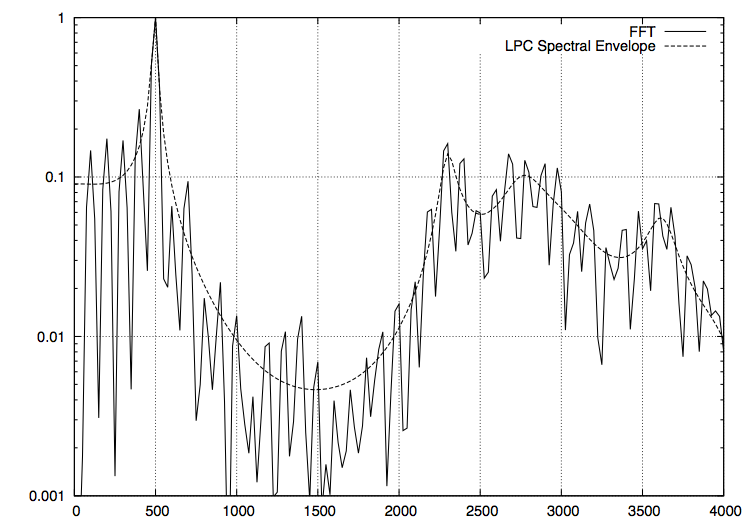
お
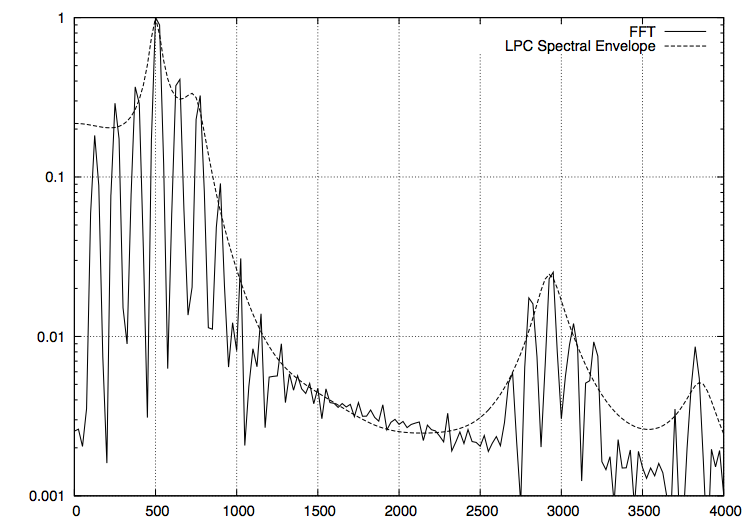
上手く取れていそうな感じがします。これを元に 40 msec 置きにフォルマントを解析した結果が以下になります。
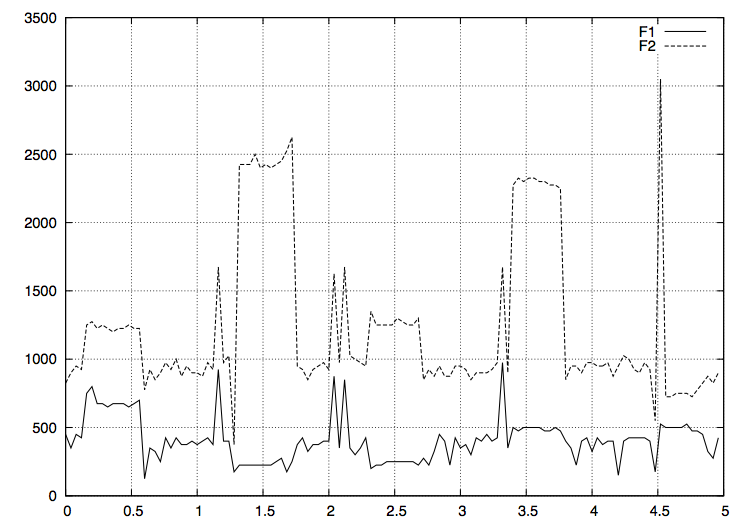
すこしガタついているようにも見えますが…。最後に、音量が閾値を超えた場合のみ、上記プログラムで母音を解析してみた結果の出力が以下になります。
- - - - あ (f1:750, f2:1250) あ (f1:800, f2:1275) あ (f1:675, f2:1225) あ (f1:675, f2:1250) あ (f1:650, f2:1225) あ (f1:675, f2:1200) あ (f1:675, f2:1225) あ (f1:675, f2:1225) あ (f1:650, f2:1250) あ (f1:675, f2:1225) あ (f1:700, f2:1225) - (f1:125, f2:775) - - - - - - - - - - - - - - - - - (f1:175, f2:375) い (f1:225, f2:2425) い (f1:225, f2:2425) い (f1:225, f2:2425) い (f1:225, f2:2500) い (f1:225, f2:2400) い (f1:225, f2:2425) い (f1:225, f2:2400) い (f1:250, f2:2425) い (f1:275, f2:2450) い (f1:175, f2:2525) い (f1:250, f2:2625) - - - - - - - - - - - - - - う (f1:200, f2:1350) う (f1:225, f2:1250) う (f1:225, f2:1250) う (f1:250, f2:1250) う (f1:250, f2:1250) う (f1:250, f2:1300) う (f1:250, f2:1275) う (f1:250, f2:1250) う (f1:250, f2:1250) う (f1:225, f2:1300) - (f1:275, f2:850) - - - - - - - - - - - - - - - - え (f1:500, f2:2275) え (f1:475, f2:2325) え (f1:500, f2:2300) え (f1:500, f2:2325) え (f1:500, f2:2325) え (f1:500, f2:2300) え (f1:475, f2:2300) え (f1:475, f2:2275) え (f1:500, f2:2275) え (f1:475, f2:2250) - - - - - - - - - - - - - - - - - - (f1:175, f2:550) - (f1:525, f2:3050) お (f1:500, f2:725) お (f1:500, f2:725) お (f1:500, f2:750) お (f1:500, f2:750) お (f1:525, f2:750) お (f1:475, f2:725) お (f1:475, f2:775) - - - -
うまく動いてますね!(これがうまく動くように周波数調整したのは内緒)
録音データからの読み取り
PortAudio は以下のように生データを持ってこれます。
#include <iostream> #include <memory> #include <portaudio.h> void check_error(PaError code) { if (code == paNoError) { return; } std::cout << Pa_GetErrorText(code) << std::endl; exit(EXIT_FAILURE); } int recordCallback( const void *input, void *output, unsigned long frameCount, const PaStreamCallbackTimeInfo* timeInfo, PaStreamCallbackFlags statusFlags, void *userData ) { auto data = reinterpret_cast<const short*>(input); for (int i = 0; i < frameCount; ++i) { std::cout << data[i] << "\n"; } std::cout << "record!" << std::endl; return 0; } int main(int argc, char* argv[]) { // 初期化 check_error( Pa_Initialize() ); std::shared_ptr<void> terminator(nullptr, [](void*) { check_error( Pa_Terminate() ); std::cout << "terminate" << std::endl; }); // ストリームを開く PaStream *stream; auto err = Pa_OpenDefaultStream( &stream, 1, 0, paInt16, 44100, 1024, recordCallback, nullptr); check_error(err); std::shared_ptr<void> closer(nullptr, [&](void*) { check_error( Pa_CloseStream(stream) ); std::cout << "close" << std::endl; }); // 録音の開始と停止 check_error( Pa_StartStream(stream) ); Pa_Sleep(3 * 1000); check_error( Pa_StopStream(stream) ); return 0; }
これを先ほどのものとガッチャンコしてみます。
そして実行したものが冒頭のムービーになります。
おわりに
次は機械学習させて精度上げるのと、Unity とのつなぎ込みをやりたいです。Unity がマイクからの生データくれるようであれば楽なので C# に書き直します。駄目ならネイティブプラグイン化で対応してみようと思います。
その他参考文献
- [http://laputa.cs.shinshu-u.ac.jp/~yizawa/InfSys1/basic/chap9/index.htm
- ハミング窓の式が載っています。
- デジタル フィルターの周波数応答 - MATLAB freqz - MathWorks 日本
- freqz の式が載っています。