はじめに
uLipSync 周りの不具合修正を行いましたので報告となります。1 つ目の issue では WebGL ビルド時に次の 2 点が問題として報告されていました。
また、別の issue では BlendShape の値についての報告がされていました。
- 現在 0 ~ 100 の値で BlendShape が計算されるが、0 ~ 1 の値で設計されたアバターにも適用したい
上記 3 点について解説します。
ダウンロード
最新版は以下になります。
WebGL ビルドでリップシンクが遅れる
こちらはリリース記事の「タイミング調整」の項でサラッ書きましたが、Audio Sync Offset Time を利用することでタイミング調整をすることができます。
WebGL ビルドでは内部的には、
- 現在再生中の
AudioClipを取得 - 現在の再生位置(
AudioSource.timeSamples)を取得 - そこから 1 フレーム再生分のバッファを
AudioClip.GetData()で取得*1 - バッファを解析アルゴリズムに投げる(同期処理)
- 解析結果をコールバックで返す
ということを行います。なので、このタイミングで返ってくる timeSamples が内部的にどのような実装になっているかによって、かなりリップシンクのタイミングが左右されます。ただ幸いなことに、非 WebGL 側で使用している現在再生中のバッファそのものを取得する MonoBehaviour.OnAudioFilterRead() とはことなり、自分でオフセットを指定できる形式なので、この取得するバッファのインデックスにオフセットをかけることができます。これが Audio Sync Offset Time となり、0.1 秒ちょっとくらいを指定しておくと、なんとなく良い感じになります。

この設定は Build Settings で Platform を WebGL に指定しているときのみ表示されます。
WebGL ビルドで AudioClip 再生後に口が開いたままになる
こちらはバグでした。。
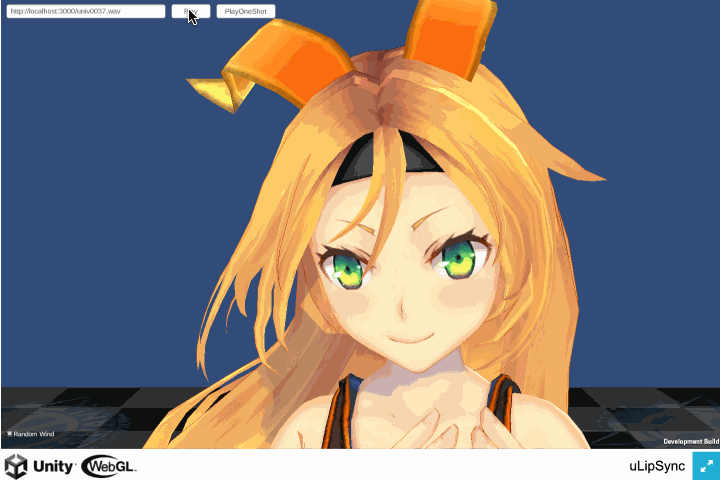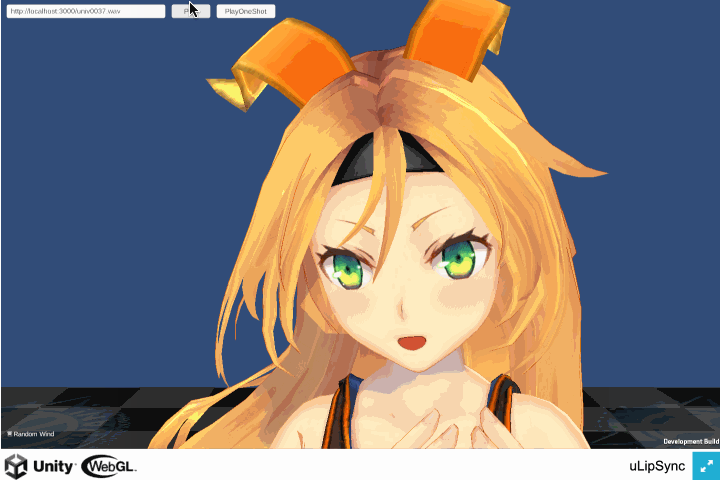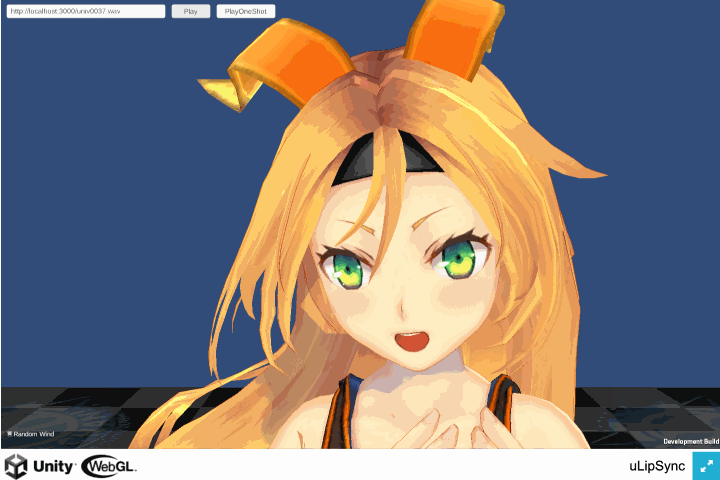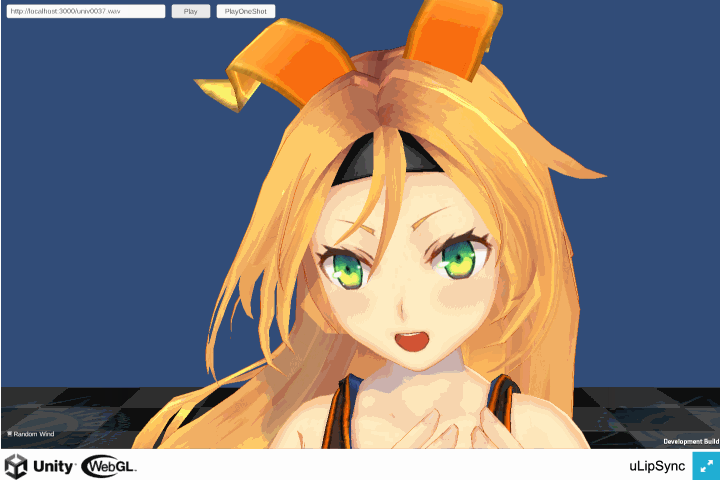
WebGL 版は AudioClip が再生されているときのみ解析が行われます*2。再生が終わると解析が行われなくなるのですが、その際使用されていたものは最後の解析結果でした。解析が行われたかどうかでフラグを立てておき、解析されてないときは Volume を 0 にして処理をスキップするようにして修正しました。
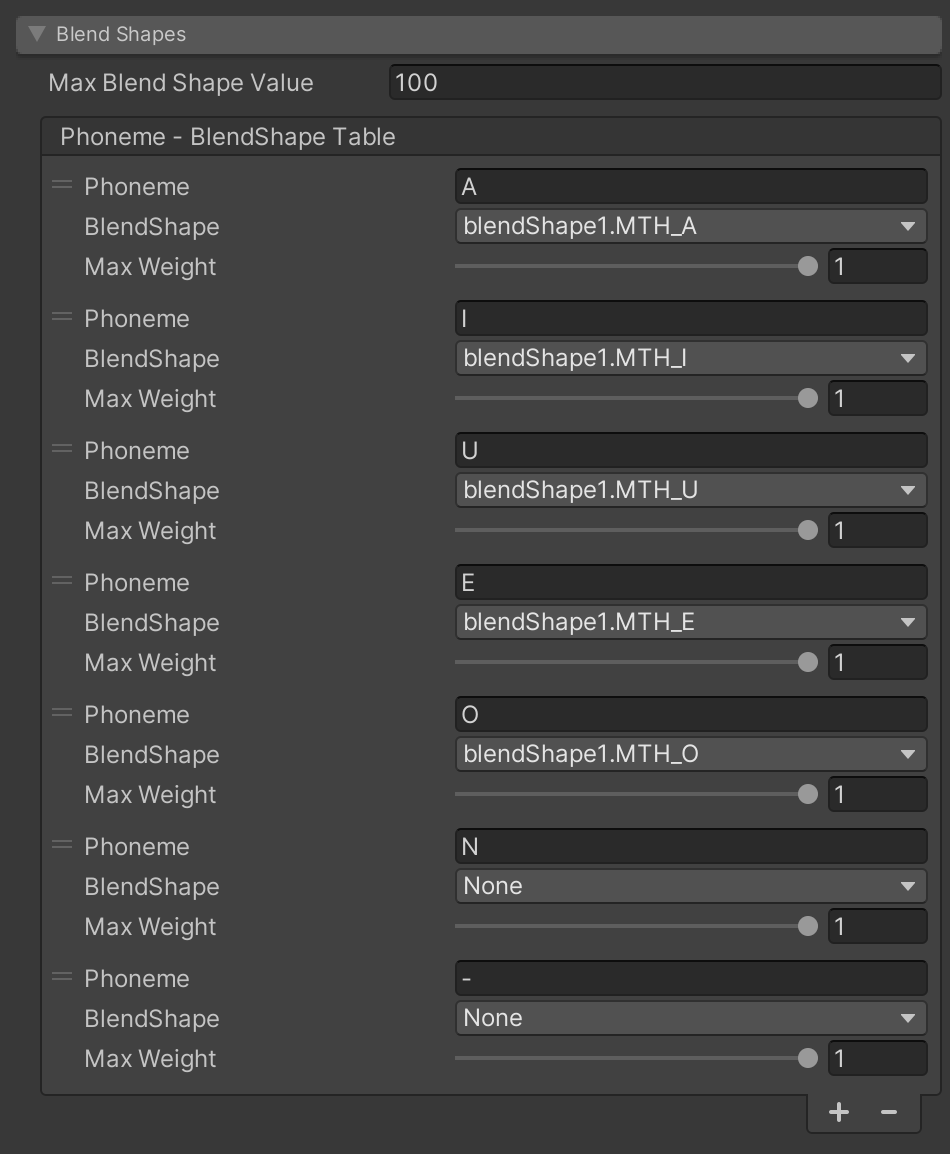
BlendShape 0 ~ 1 の値で設計されたアバター対応
ユニティちゃんなどを見て、BlendShape を 0 ~ 100(100 で各 BlendShape の反映度合いが最大)と仮定して設計していましたが、Ready Palyer Me のようなサービスで作られたアバターは 0 ~ 1 となっているとの報告をもらいました。
これに対応するために、この 100 / 1 といった最大の BlendShape 値をインスペクタから設定できるようにしました。
おわりに
次回は uMicrophoneWebGL とのつなぎについての解説を行います。