はじめに

コンピュートシェーダを使った GPU パーティクルを試してみます。GPU パーティクルを出す方法はいくつかあるのですが、任意のメッシュを利用したかったため、コンピュートシェーダを使った擬似インスタンシングによる方法を利用してみました。
スクリーンスペースでの衝突および任意のタイミングでの生成・消滅をさせるところまでやってみました。
デモ
コード
環境
- Windows 10
- Unity 5.4.0b17
コンピュートシェーダの基礎
こちらのページで翻訳されている ScrawkBlog がとてもわかり易い解説でした。
コンピュートシェーダの簡単な利用方法から、ComputeBuffer の利用方法として、通常の Buffer から、Append Buffer、Consume Buffer、最近の記事では Counter Buffer について解説されています。コードが Unity 5.4 ベースなのでご注意下さい。
擬似インスタンシング
登録したメッシュを頂点数の限界の 65534 頂点以内に収まるように結合して、適当な空き UV にそれぞれの結合したメッシュの ID を登録、その ID を利用して頂点シェーダでコンピュートシェーダで計算した情報を使って移動・回転・拡縮します。
65534 頂点を超える場合は、複数のマテリアルを作成し、それぞれのマテリアルにコンピュートシェーダから取り出す際の ID のオフセットを仕込んでおき、そのマテリアルを使ってメッシュを複数回描画します。任意のメッシュを使う方法としては、Unity 5.1 から追加された CommandBuffer.DrawProcedural() を利用したインスタンシングの方が、任意の描画タイミングに実行可能で且つ 65000 頂点の限界を超えられるとのことで、こちらのほうが素性が良いかもしれません(メッシュの結合過程が不要、以前は即時実行する Graphics.DrawProcedural()、Graphics.DrawProceduralIndirect() しかなかった)。
こちらは次回試してみたいと思います。
コード
コンピュートシェーダ
初期化、消滅したあとに再初期化、更新の役割を担う 3 つのカーネルがあります。やっていることはとても単純で、パラメタの初期化と、時間に応じて速度・位置・回転・スケールを変更しているだけです。まずは簡単のために、消滅したら即再生成する(time が lifeTime を超えたら active が false になり、それを Emit() で検知して再度 Init() を行う)形で書いてみます
#pragma kernel Init #pragma kernel Emit #pragma kernel Update struct Particle { int id; bool active; float3 position; float3 velocity; float3 rotation; float3 angVelocity; float scale; float time; float lifeTime; }; RWStructuredBuffer<Particle> _Particles; float _DeltaTime; float4 _Range; float4 _Velocity; float4 _AngVelocity; float rand(float2 seed) { return frac(sin(dot(seed.xy, float2(12.9898, 78.233))) * 43758.5453); } float3 rand3(float2 seed) { return 2.0 * (float3(rand(seed * 1), rand(seed * 2), rand(seed * 3)) - 0.5); } [numthreads(8, 1, 1)] void Init(uint id : SV_DispatchThreadID) { float2 seed = float2(id + 1, id + 2); float3 pos = rand3(seed); float3 rot = rand3(seed + 3); Particle p = _Particles[id]; p.id = id; p.active = true; p.position = pos * _Range.xyz; p.velocity = pos * _Velocity.xyz; p.rotation = rot * _AngVelocity.xyz; p.angVelocity = rot * _AngVelocity.xyz; p.scale = 0.1; p.time = 0.0; p.lifeTime = 2.0 + rand(seed * 7) * 2.0; _Particles[id] = p; } [numthreads(8, 1, 1)] void Emit(uint id : SV_DispatchThreadID) { if (!_Particles[id].active) Init(id); } [numthreads(8, 1, 1)] void Update(uint id : SV_DispatchThreadID) { Particle p = _Particles[id]; if (p.time < p.lifeTime) { p.active = true; p.time += _DeltaTime; p.position += p.velocity * _DeltaTime; p.velocity.y += -9.8 * _DeltaTime; p.rotation += p.angVelocity * _DeltaTime; p.scale = (1.0 - pow(p.time / p.lifeTime, 3.0)) * 0.1; } else { p.active = false; } _Particles[id] = p; }
スクリプト
このコンピュートシェーダをスクリプトから呼び出します。CreateCombindMesh() で 65534 頂点に収まるように結合しています。例えばここで 100 個のメッシュが収まり、10000 個のパーティクルを出したいのであれば、100 個のマテリアルを作成して、それぞれ _IdOffset に何個目のマテリアルから開始するか、という情報を Material.SetInt() しておき、コンピュートシェーダから受け取ったパーティクルの計算結果の配列アクセスにオフセットをかけて取り出すようにします。これは、Graphics.DrawMesh() が即時実行ではなく、後のレンダリングのタイミングで実行されるため、その場で書き換えてしまうと最後にセットしたオフセットが全ての描画に使われてしまうからです。
マテリアルを増やしたくない場合は MaterialPropertyBlock を使う方法があって、これは Set***() 系の関数でプロパティをセット出来るオブジェクトで、これを DrawMesh() のタイミングで同時に渡すことにより、同じマテリアルでパラメタだけ異なる描画を行うことが出来ます。ただ Graphics.DrawMesh() のオーバーロードで描画するカメラを指定する必要があるので、シーンビューにも出そうとするとそちらのカメラも取ってこないとなりません。GitHub に上げたコードではこちらを利用しています。
using UnityEngine; using UnityEngine.Assertions; using System.Collections.Generic; using System.Runtime.InteropServices; struct Particle { public int id; public bool active; public Vector3 position; public Vector3 velocity; public Vector3 rotation; public Vector3 angVelocity; public float scale; public float time; public float lifeTime; } public class PseudoInstancedGPUParticleManager : MonoBehaviour { const int MAX_VERTEX_NUM = 65534; [SerializeField, Tooltip("This cannot be changed while running.")] int maxParticleNum; [SerializeField] Mesh mesh; [SerializeField] Shader shader; [SerializeField] ComputeShader computeShader; [SerializeField] Vector3 velocity = new Vector3(2f, 5f, 2f); [SerializeField] Vector3 angVelocity = new Vector3(45f, 45f, 45f); [SerializeField] Vector3 range = Vector3.one; Mesh combinedMesh_; ComputeBuffer computeBuffer_; int updateKernel_; int emitKernel_; List<Material> materials_ = new List<Material>(); int particleNumPerMesh_; int meshNum_; Mesh CreateCombinedMesh(Mesh mesh, int num) { Assert.IsTrue(mesh.vertexCount * num <= MAX_VERTEX_NUM); var meshIndices = mesh.GetIndices(0); var indexNum = meshIndices.Length; var vertices = new List<Vector3>(); var indices = new int[num * indexNum]; var normals = new List<Vector3>(); var tangents = new List<Vector4>(); var uv0 = new List<Vector2>(); var uv1 = new List<Vector2>(); for (int id = 0; id < num; ++id) { vertices.AddRange(mesh.vertices); normals.AddRange(mesh.normals); tangents.AddRange(mesh.tangents); uv0.AddRange(mesh.uv); // 各メッシュのインデックスは(1 つのモデルの頂点数 * ID)分ずらす for (int n = 0; n < indexNum; ++n) { indices[id * indexNum + n] = id * mesh.vertexCount + meshIndices[n]; } // 2 番目の UV に ID を格納しておく for (int n = 0; n < mesh.uv.Length; ++n) { uv1.Add(new Vector2(id, id)); } } var combinedMesh = new Mesh(); combinedMesh.SetVertices(vertices); combinedMesh.SetIndices(indices, MeshTopology.Triangles, 0); combinedMesh.SetNormals(normals); combinedMesh.RecalculateNormals(); combinedMesh.SetTangents(tangents); combinedMesh.SetUVs(0, uv0); combinedMesh.SetUVs(1, uv1); combinedMesh.RecalculateBounds(); combinedMesh.bounds.SetMinMax(Vector3.one * -100f, Vector3.one * 100f); return combinedMesh; } void OnEnable() { particleNumPerMesh_ = MAX_VERTEX_NUM / mesh.vertexCount; meshNum_ = (int)Mathf.Ceil((float)maxParticleNum / particleNumPerMesh_); for (int i = 0; i < meshNum_; ++i) { var material = new Material(shader); material.SetInt("_IdOffset", particleNumPerMesh_ * i); materials_.Add(material); } combinedMesh_ = CreateCombinedMesh(mesh, particleNumPerMesh_); computeBuffer_ = new ComputeBuffer(maxParticleNum, Marshal.SizeOf(typeof(Particle)), ComputeBufferType.Default); var initKernel = computeShader.FindKernel("Init"); updateKernel_ = computeShader.FindKernel("Update"); emitKernel_ = computeShader.FindKernel("Emit"); computeShader.SetBuffer(initKernel, "_Particles", computeBuffer_); computeShader.SetVector("_Velocity", velocity); computeShader.SetVector("_AngVelocity", angVelocity * Mathf.Deg2Rad); computeShader.SetVector("_Range", range); computeShader.Dispatch(initKernel, maxParticleNum / 8, 1, 1); } void OnDisable() { computeBuffer_.Release(); } void Update() { computeShader.SetVector("_Velocity", velocity); computeShader.SetVector("_AngVelocity", angVelocity * Mathf.Deg2Rad); computeShader.SetVector("_Range", range); computeShader.SetBuffer(emitKernel_, "_Particles", computeBuffer_); computeShader.Dispatch(emitKernel_, maxParticleNum / 8, 1, 1); computeShader.SetFloat("_DeltaTime", Time.deltaTime); computeShader.SetBuffer(updateKernel_, "_Particles", computeBuffer_); computeShader.Dispatch(updateKernel_, maxParticleNum / 8, 1, 1); for (int i = 0; i < meshNum_; ++i) { var material = materials_[i]; material.SetInt("_IdOffset", particleNumPerMesh_ * i); material.SetBuffer("_Particles", computeBuffer_); Graphics.DrawMesh(combinedMesh_, transform.position, transform.rotation, material, 0); } } }
描画
最後にこれを描画します。Deferred レンダリング用に GBuffer の情報も出力しています。また、ShadowCaster のパスを追加して、適切に影が落ちるようにしています。
Shader "GPUParticle/PseudoInstancedGPUParticle" { SubShader { Tags { "RenderType" = "Opaque" } CGINCLUDE #include "UnityCG.cginc" #include "UnityStandardShadow.cginc" struct Particle { int id; bool active; float3 position; float3 velocity; float3 rotation; float3 angVelocity; float scale; float time; float lifeTime; }; #ifdef SHADER_API_D3D11 StructuredBuffer<Particle> _Particles; #endif int _IdOffset; struct appdata { float4 vertex : POSITION; float3 normal : NORMAL; float2 uv1 : TEXCOORD1; }; struct v2f { float4 position : SV_POSITION; float3 normal : NORMAL; float2 uv1 : TEXCOORD1; }; struct v2f_shadow { V2F_SHADOW_CASTER; }; struct gbuffer_out { float4 diffuse : SV_Target0; // rgb: diffuse, a: occlusion float4 specular : SV_Target1; // rgb: specular, a: smoothness float4 normal : SV_Target2; // rgb: normal, a: unused float4 emission : SV_Target3; // rgb: emission, a: unused float depth : SV_Depth; }; inline int getId(float2 uv1) { return (int)(uv1.x + 0.5) + _IdOffset; } float3 rotate(float3 p, float3 rotation) { float3 a = normalize(rotation); float angle = length(rotation); if (abs(angle) < 0.001) return p; float s = sin(angle); float c = cos(angle); float r = 1.0 - c; float3x3 m = float3x3( a.x * a.x * r + c, a.y * a.x * r + a.z * s, a.z * a.x * r - a.y * s, a.x * a.y * r - a.z * s, a.y * a.y * r + c, a.z * a.y * r + a.x * s, a.x * a.z * r + a.y * s, a.y * a.z * r - a.x * s, a.z * a.z * r + c ); return mul(m, p); } v2f vert(appdata v) { #ifdef SHADER_API_D3D11 Particle p = _Particles[getId(v.uv1)]; v.vertex.xyz *= p.scale; v.vertex.xyz = rotate(v.vertex.xyz, p.rotation); v.vertex.xyz += p.position; v.normal = rotate(v.normal, p.rotation); #endif v2f o; o.uv1 = v.uv1; o.position = mul(UNITY_MATRIX_VP, v.vertex); o.normal = v.normal; return o; } gbuffer_out frag(v2f i) : SV_Target { Particle p; #ifdef SHADER_API_D3D11 p = _Particles[getId(i.uv1)]; #endif float3 v = p.velocity; gbuffer_out o; o.diffuse = float4(v.y * 0.5, (abs(v.x) + abs(v.z)) * 0.1, -v.y * 0.5, 0); o.normal = float4(i.normal, 1); o.emission = o.diffuse * 0.1; o.specular = 0; o.depth = i.position; return o; } v2f_shadow vert_shadow(appdata v) { #ifdef SHADER_API_D3D11 Particle p = _Particles[getId(v.uv1)]; v.vertex.xyz = rotate(v.vertex.xyz, p.rotation); v.vertex.xyz *= p.scale; v.vertex.xyz += p.position; #endif v2f_shadow o; TRANSFER_SHADOW_CASTER_NORMALOFFSET(o) o.pos = mul(UNITY_MATRIX_VP, v.vertex); return o; } float4 frag_shadow(v2f_shadow i) : SV_Target { SHADOW_CASTER_FRAGMENT(i) } ENDCG Pass { Tags { "LightMode" = "Deferred" } ZWrite On CGPROGRAM #pragma target 3.0 #pragma vertex vert #pragma fragment frag ENDCG } Pass { Tags { "LightMode" = "ShadowCaster" } Fog { Mode Off } ZWrite On ZTest LEqual Cull Off Offset 1, 1 CGPROGRAM #pragma target 3.0 #pragma vertex vert_shadow #pragma fragment frag_shadow #pragma multi_compile_shadowcaster #pragma fragmentoption ARB_precision_hint_fastest ENDCG } } FallBack "Diffuse" }
結果
最初は 1 メッシュ、次が 30000 個のキューブを表示したところです。
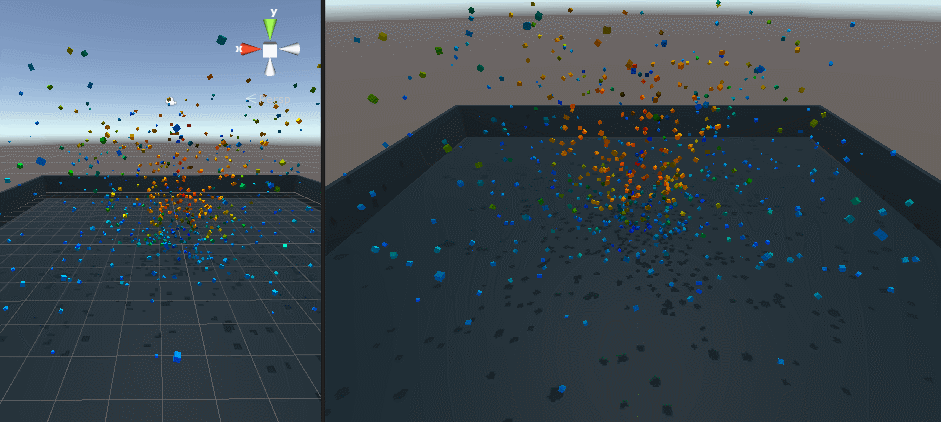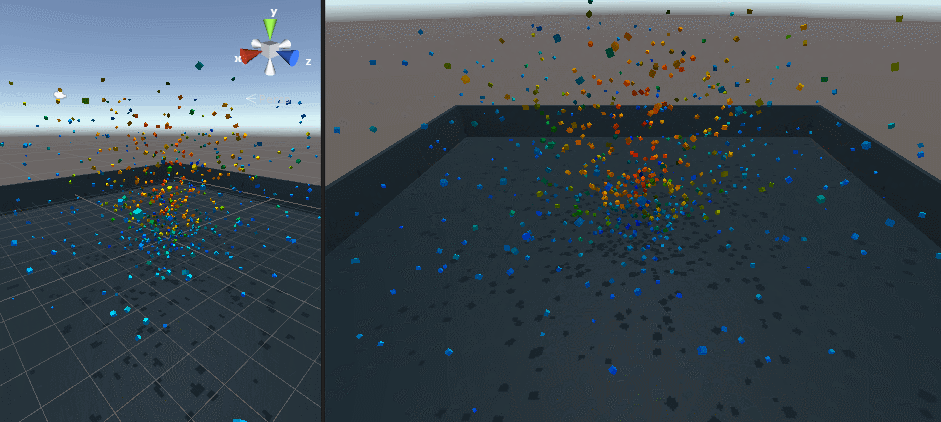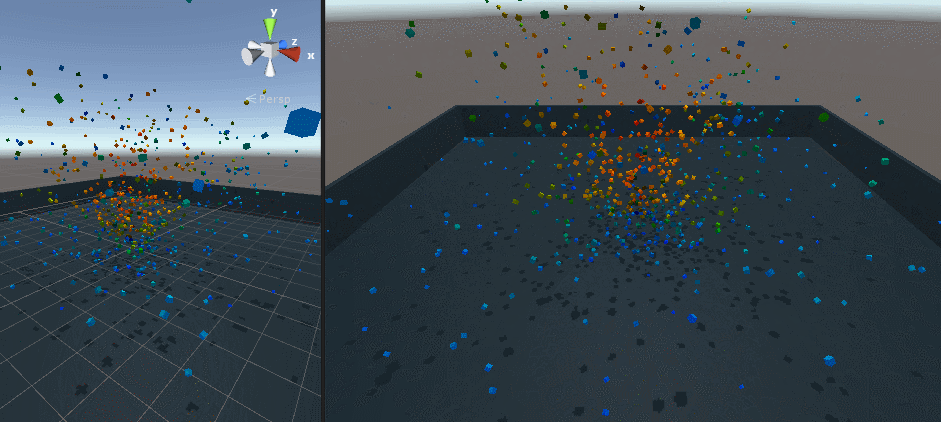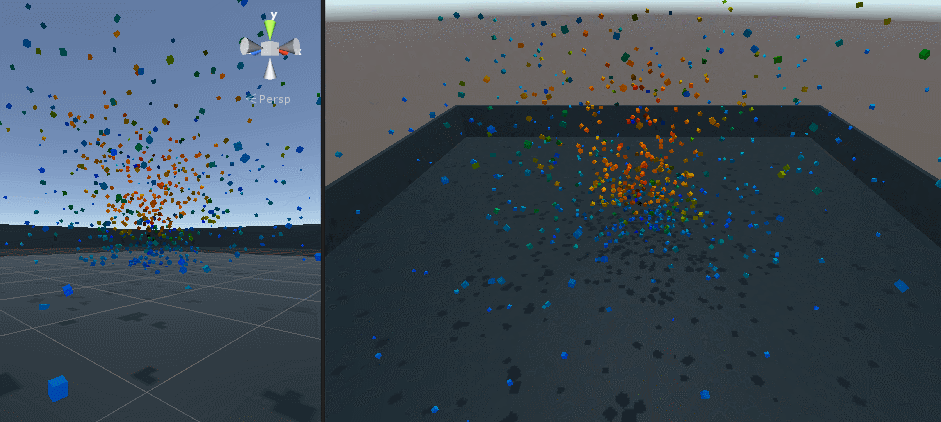
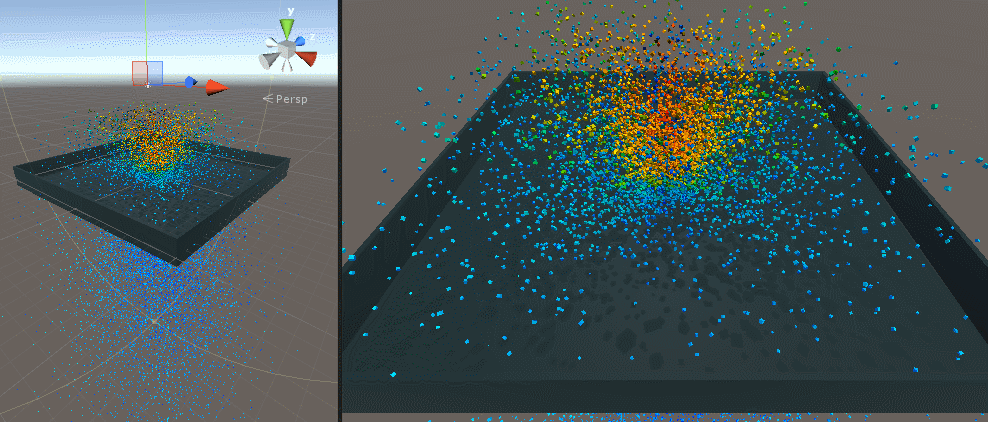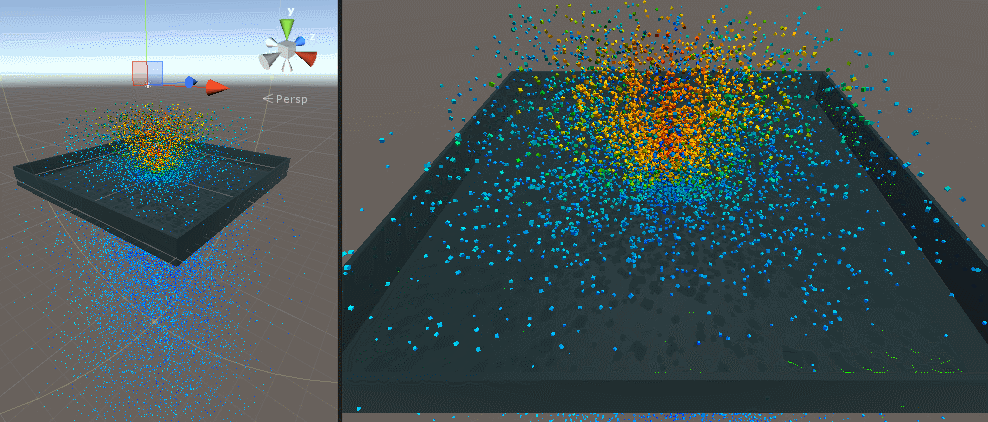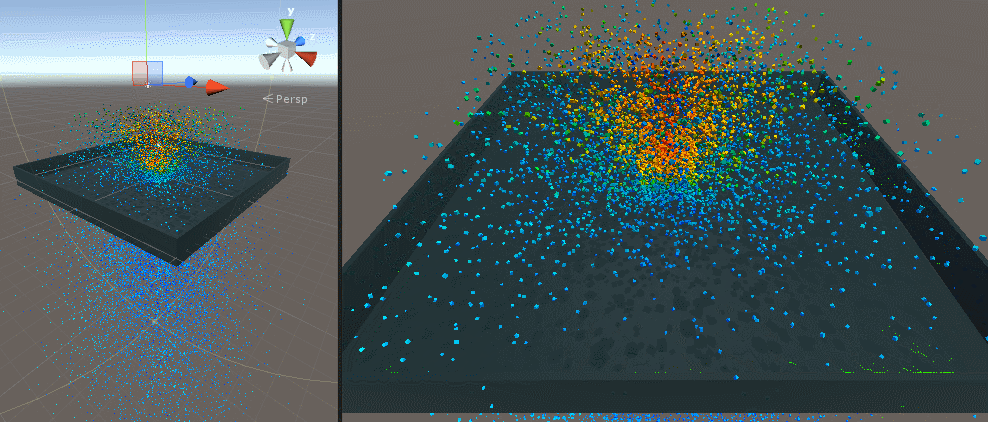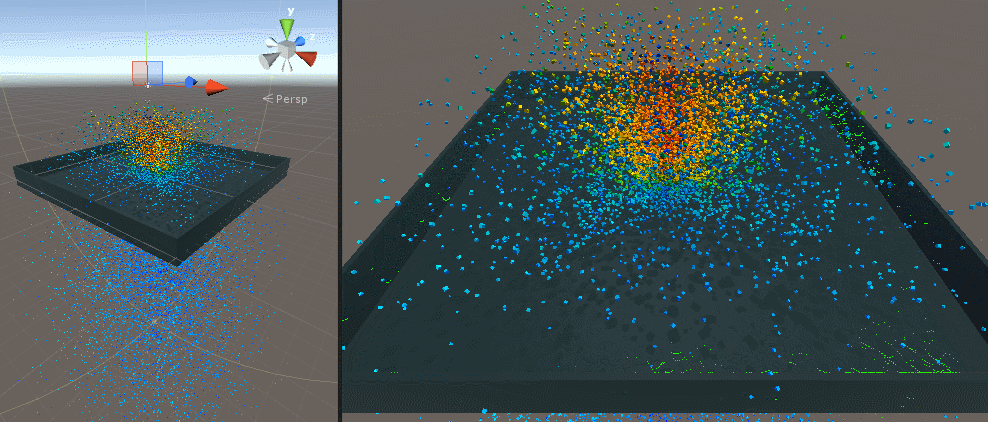
Screen Space Collision
G-Buffer からデプス及び法線を取り出し、これを利用してパーティクルの衝突を実装します。カメラから見える(遮蔽されてない)範囲でのみ正しい衝突が行えます。
G-Buffer を Compute Shader へ渡す
Command Buffer を使って取ってきても良いと思いますが、ここは描画後(WaitForEndOfFrame()後)のタイミングで G-Buffer を RenderTexture へコピーしてきます。
G-Buffer コピー用のスクリプト
using UnityEngine; using UnityEngine.Assertions; using System.Collections; public class GBufferUtils : MonoBehaviour { static GBufferUtils Instance; [SerializeField] Shader gbufferCopyShader; Material gbufferCopyMaterial_; Mesh quad_; RenderTexture depthTexture_; RenderTexture[] gbufferTextures_ = new RenderTexture[4]; static new Camera camera { get { return Camera.main; } } static public GBufferUtils GetInstance() { Assert.IsTrue(Instance != null, "At least one GBufferUtils must be attached to a camera and be set as active."); return Instance; } static public RenderTexture GetDepthTexture() { return GetInstance().depthTexture_; } static public RenderTexture GetGBufferTexture(int index) { Assert.IsTrue(index >= 0 && index < 4); return GetInstance().gbufferTextures_[index]; } Mesh CreateQuad() { var mesh = new Mesh(); mesh.name = "Quad"; mesh.vertices = new Vector3[4] { new Vector3( 1f, 1f, 0f), new Vector3(-1f, 1f, 0f), new Vector3(-1f,-1f, 0f), new Vector3( 1f,-1f, 0f), }; mesh.triangles = new int[6] { 0, 1, 2, 2, 3, 0 }; return mesh; } RenderTexture CreateRenderTexture(RenderTextureFormat format, int depth) { var texture = new RenderTexture(camera.pixelWidth, camera.pixelHeight, depth, format); texture.filterMode = FilterMode.Point; texture.useMipMap = false; texture.generateMips = false; texture.enableRandomWrite = false; texture.Create(); return texture; } void Start() { quad_ = CreateQuad(); gbufferCopyMaterial_ = new Material(gbufferCopyShader); } void OnEnable() { Assert.IsTrue(Instance == null, "Multiple GBUfferUtils are set as active at the same time."); Instance = this; UpdateRenderTextures(); } void OnDisable() { Instance = null; if (depthTexture_ != null) { depthTexture_.Release(); depthTexture_ = null; } for (int i = 0; i < 4; ++i) { if (gbufferTextures_[i] != null) { gbufferTextures_[i].Release(); gbufferTextures_[i] = null; } } } IEnumerator OnPostRender() { yield return new WaitForEndOfFrame(); UpdateRenderTextures(); UpdateGBuffer(); } void UpdateRenderTextures() { if (depthTexture_ == null || depthTexture_.width != camera.pixelWidth || depthTexture_.height != camera.pixelHeight) { if (depthTexture_ != null) depthTexture_.Release(); depthTexture_ = CreateRenderTexture(RenderTextureFormat.Depth, 24); } for (int i = 0; i < 4; ++i) { if (gbufferTextures_[i] == null || gbufferTextures_[i].width != camera.pixelWidth || gbufferTextures_[i].height != camera.pixelHeight) { if (gbufferTextures_[i] != null) gbufferTextures_[i].Release(); gbufferTextures_[i] = CreateRenderTexture(RenderTextureFormat.ARGB32, 0); } } } void UpdateGBuffer() { var gbuffers = new RenderBuffer[4]; for (int i = 0; i < 4; ++i) { gbuffers[i] = gbufferTextures_[i].colorBuffer; } gbufferCopyMaterial_.SetPass(0); Graphics.SetRenderTarget(gbuffers, depthTexture_.depthBuffer); Graphics.DrawMeshNow(quad_, Matrix4x4.identity); Graphics.SetRenderTarget(null); } }
G-Buffer コピー用のシェーダ
Shader "Hidden/GBufferCopy" { CGINCLUDE #include "UnityCG.cginc" sampler2D _CameraGBufferTexture0; // rgb: diffuse, a: occlusion sampler2D _CameraGBufferTexture1; // rgb: specular, a: smoothness sampler2D _CameraGBufferTexture2; // rgb: normal, a: unused sampler2D _CameraGBufferTexture3; // rgb: emission, a: unused sampler2D_float _CameraDepthTexture; struct appdata { float4 vertex : POSITION; }; struct v2f { float4 vertex : SV_POSITION; float4 screenPos : TEXCOORD0; }; struct gbuffer_out { float4 diffuse : SV_Target0; // rgb: diffuse, a: occlusion float4 specular : SV_Target1; // rgb: specular, a: smoothness float4 normal : SV_Target2; // rgb: normal, a: unused float4 emission : SV_Target3; // rgb: emission, a: unused float depth : SV_Depth; }; v2f vert(appdata v) { v2f o; o.vertex = v.vertex; o.screenPos = v.vertex; #if UNITY_UV_STARTS_AT_TOP o.screenPos.y *= -1.0; #endif return o; } gbuffer_out frag(v2f v) { float2 uv = (v.screenPos * 0.5 + 0.5); gbuffer_out o; o.diffuse = tex2D(_CameraGBufferTexture0, uv); o.specular = tex2D(_CameraGBufferTexture1, uv); o.normal = tex2D(_CameraGBufferTexture2, uv); o.emission = tex2D(_CameraGBufferTexture3, uv); o.depth = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, uv) ; return o; } ENDCG SubShader { Tags { "RenderType" = "Opaque" } Blend Off ZTest Always ZWrite On Cull Off Pass { CGPROGRAM #pragma vertex vert #pragma fragment frag ENDCG } } }
コンピュートシェーダへ与える部分
得られた G-Buffer をコンピュートシェーダへ与えます。UV 座標を計算するためにビュー・プロジェクション行列が必要なので同時に与えておきます。SetMatrix() はないのですが、SetFloats() で配列を渡しておけば、Compute Shader 内では float4x4 で受け取ることができます。
var view = camera.worldToCameraMatrix; var proj = GL.GetGPUProjectionMatrix(camera.projectionMatrix, false); var vp = proj * view; computeShader.SetFloats("_ViewProj", new float[] { vp.m00, vp.m10, vp.m20, vp.m30, vp.m01, vp.m11, vp.m21, vp.m31, vp.m02, vp.m12, vp.m22, vp.m32, vp.m03, vp.m13, vp.m23, vp.m33 }); computeShader.SetTexture(updateKernel_, "_CameraDepthTexture", GBufferUtils.GetDepthTexture()); computeShader.SetTexture(updateKernel_, "_CameraGBufferTexture2", GBufferUtils.GetGBufferTexture(2));
スクリーンスペース衝突有りのコンピュートシェーダ
長くないので全コードを載せると以下のようになっています。
#pragma kernel Init #pragma kernel Emit #pragma kernel Update #include "UnityCG.cginc" struct Particle { int id; bool active; float3 position; float3 velocity; float3 rotation; float3 angVelocity; float4 color; float scale; float time; float lifeTime; }; RWStructuredBuffer<Particle> _Particles; float _DeltaTime; float _ScreenWidth; float _ScreenHeight; float4 _Range; float4 _Velocity; float4 _AngVelocity; float _Scale; float4x4 _ViewProj; Texture2D<float> _CameraDepthTexture; Texture2D<float4> _CameraGBufferTexture2; inline float GetDepth(float2 uv) { float2 coord = float2(uv.x * _ScreenWidth, uv.y * _ScreenHeight); return _CameraDepthTexture[coord].r; } inline float3 GetNormal(float2 uv) { float2 coord = float2(uv.x * _ScreenWidth, uv.y * _ScreenHeight); return _CameraGBufferTexture2[coord].rgb * 2.0 - 1.0; } inline float ComputeDepth(float4 pos) { #if defined(SHADER_TARGET_GLSL) || defined(SHADER_API_GLES) || defined(SHADER_API_GLES3) return (pos.z / pos.w) * 0.5 + 0.5; #else return pos.z / pos.w; #endif } inline float rand(float2 seed) { return frac(sin(dot(seed.xy, float2(12.9898, 78.233))) * 43758.5453); } inline float3 rand3(float2 seed) { return 2.0 * (float3(rand(seed * 1), rand(seed * 2), rand(seed * 3)) - 0.5); } [numthreads(8, 1, 1)] void Init(uint id : SV_DispatchThreadID) { float2 seed = float2(id + 1, id + 2); float3 position = rand3(seed); float3 velocity = rand3(seed + 1); float3 rotation = rand3(seed + 2); Particle p = _Particles[id]; p.id = id; p.active = true; p.position = position * _Range.xyz; p.velocity = velocity * _Velocity.xyz; p.rotation = rotation * _AngVelocity.xyz; p.angVelocity = rotation * _AngVelocity.xyz; p.color = 0; p.scale = 1.0; p.time = 0.0; p.lifeTime = 3.0 + rand(seed + 3) * 3.0; _Particles[id] = p; } [numthreads(8, 1, 1)] void Emit(uint id : SV_DispatchThreadID) { if (!_Particles[id].active) Init(id); } [numthreads(8, 1, 1)] void Update(uint id : SV_DispatchThreadID) { Particle p = _Particles[id]; if (p.time < p.lifeTime) { float3 nextPos = p.position + p.velocity * _DeltaTime; float4 vpPos = mul(_ViewProj, float4(nextPos, 1.0)); float2 uv = vpPos.xy / vpPos.w * 0.5 + 0.5; float gbufferDepth = GetDepth(uv); float particleDepth = vpPos.z / vpPos.w; float3 normal = GetNormal(uv); if (particleDepth > gbufferDepth) { p.velocity -= dot(p.velocity, normal) * normal * 1.99 /* 1.0 + bouciness */; } p.time += _DeltaTime; p.velocity.y += -9.8 * _DeltaTime; p.position += p.velocity * _DeltaTime; p.scale = (1.0 - pow(p.time / p.lifeTime, 3.0)) * _Scale; p.rotation += p.angVelocity * _DeltaTime; float speed = length(p.velocity) / 5; p.color = float4(0, speed, pow(p.time / p.lifeTime, 2), 1); } else { p.active = false; } _Particles[id] = p; }
結果
500 個、10 万個、120 万個(矩形ポリゴン)で試してみました。パーティクル自体のデプスも G-Buffer に書き込んでいるので結構ワシャワシャしています。


G-Buffer へ書き込むのをやめるとライティングはされなくなりますが壁だけに反射するようになります。ShadowCaster もしなくなればもっと大量のパーティクルを出しても軽量だと思います。

生成と消滅
このままでは、消滅したら即生成して指定したパーティクルがずっと生じる状態になってしまっています。これを適当なタイミングに発射できるように変更するため、いくらか手を加えます。
Append Buffer と Consume Buffer
Append Buffer と Consume Buffer はそれぞれ追加・取り出し可能な LIFO なコンテナです。これまでは、active フラグのみで生死管理していた仕組みを、代わりにこれらを使ってパーティクルプールを作り、そこから取り出して生成するようにしてみます。Buffer についての説明は以下のエントリをご参照ください。
- https://scrawkblog.com/2014/08/14/directcompute-tutorial-for-unity-append-buffers/
- https://scrawkblog.com/2014/09/04/directcompute-tutorial-for-unity-consume-buffers/
パーティクルの仕組みは以下の GDC のスライドを参考にしています。
今回は不透明な G-Buffer 書き込み有りのパーティクルのため、ソートはしていません。
細かい実装の解説は長くなるため省略します。詳細は GitHub に上げたコードをご参照ください。
コンピュートシェーダ
変更した内容だけ抜粋します。
... AppendStructuredBuffer<uint> _DeadList; ConsumeStructuredBuffer<uint> _ParticlePool; ... [numthreads(8, 1, 1)] void Init(uint id : SV_DispatchThreadID) { _Particles[id].active = false; _DeadList.Append(id); } [numthreads(8, 1, 1)] void Emit() { uint id = _ParticlePool.Consume(); Particle p = _Particles[id]; ... _Particles[id] = p; } [numthreads(8, 1, 1)] void Update(uint id : SV_DispatchThreadID) { Particle p = _Particles[id]; if (p.active) { ... if (p.time > p.lifeTime) { p.active = false; _DeadList.Append(id); } } else { p.scale = 0; } _Particles[id] = p; }
_DeadList と _ParticlePool は外からは同じバッファを与えます。Append() するときは AppendStructuredBuffer、Consume() するときは ConsumeStructuredBuffer を使うため、違う名前を与えているだけです。
スクリプト
... ComputeBuffer particlePoolBuffer_; ComputeBuffer particleArgsBuffer_; int[] particleArgs_; ... int GetParticlePoolSize() { particleArgsBuffer_.SetData(particleArgs_); ComputeBuffer.CopyCount(particlePoolBuffer_, particleArgsBuffer_, 0); particleArgsBuffer_.GetData(particleArgs_); return particleArgs_[0]; } ... void OnEnable() { particlesBuffer_ = new ComputeBuffer(maxParticleNum, Marshal.SizeOf(typeof(Particle)), ComputeBufferType.Default); ... particlePoolBuffer_ = new ComputeBuffer(maxParticleNum, sizeof(int), ComputeBufferType.Append); particlePoolBuffer_.SetCounterValue(0); ... particleArgsBuffer_ = new ComputeBuffer(4, sizeof(int), ComputeBufferType.IndirectArguments); particleArgs_ = new int[] { 0, 1, 0, 0 }; ... computeShader.SetBuffer(initKernel, "_Particles", particlesBuffer_); computeShader.SetBuffer(initKernel, "_DeadList", particlePoolBuffer_); computeShader.Dispatch(initKernel, maxParticleNum / 8, 1, 1); ... } ... void Update() { ... var emitGroupNum = 10; // 10 グループ(= 80個)のパーティクルを発生 computeShader.SetBuffer(emitKernel_, "_Particles", particlesBuffer_); computeShader.SetBuffer(emitKernel_, "_ParticlePool", particlePoolBuffer_); computeShader.Dispatch(emitKernel_, Mathf.Min(emitGroupNum, GetParticlePoolSize() / 8), 1, 1); ... computeShader.SetBuffer(updateKernel_, "_Particles", particlesBuffer_); computeShader.SetBuffer(updateKernel_, "_DeadList", particlePoolBuffer_); computeShader.Dispatch(updateKernel_, maxParticleNum / 8, 1, 1); ... }
プールが空なのにもかかわらず Consume() すると予期しない動作(e.g. ディスプレイドライバの応答が停止)を引き起こすので、それをチェックするために ComputeBuffer.CopyCount() を使って、パーティクルプールに何個使用可能なパーティクルがあるかを調べて、それを超えないように Emit カーネルを実行しています。細かい端数は無視してグループ単位で与えているだけの実装にしました。
結果

おわりに
描画必要のない(active が false)パーティクルは描画されない(=フラグメントシェーダが走らない)よう scale を 0 にしているのですが、無駄な頂点シェーダの処理は走っています。こういった観点からも本手法ではなく、DrawProcedural() で必要なインスタンス数分だけ描画する方が素性が良いと思われます。次回はこれをやってみます。