はじめに
ずっとやろうと思っていた Unity でリップシンクを実現するアセットである uLipSync のアルゴリズムの改善を行いました。
uLipSyncでは、MFCC(Mel Frequency Cepstral Coefficients)と呼ばれる特徴量を計算しています。MFCC を利用することで音声信号から音素の違い(母音や子音など)や楽器の音色の違いを区別することができ、音声認識や音楽情報検索など、様々な音声・音楽処理タスクで広く利用されています。Python 環境では Librosa などのライブラリを使って MFCC は簡単に計算することが出来ます。
一方 uLipSync では、Unity 内でネイティブプラグインなどに頼らず JobSystem + Burst コンパイラの助けを借りて高速に処理したいコンセプトがある関係上、こういったライブラリに頼ることは出来ず、すべての計算をゼロから書かないとなりませんでした。計算した結果をエディタ拡張で図示して何となくそれっぽく値が出ており、かつ MFCC を特徴量として事前に取得しておいた音声の MFCC と比較することで音素判別がそれなりに出来ていたので、書いたコードは合ってるかなと思っていたのですが...、今回改めてこちらを検証しました。
記事としては解説記事というか、備忘録になります。なので内容は多くの方には余り意味のある内容ではないかと思います。。現在 v3.0.0 のリリース準備中のため、来月リリースしその記事を書きます。
改善後の様子
「あーいーうーえーおー、あいうえお、こんにちは」と喋っています。前より識別性能が良くなりました。

検証
結論からいうと...、計算が....間違っていました...。最も駄目だったのは、メルフィルタバンクと呼ばれる人間の聴覚特性に基づいた周波数のまとまりを計算するためのところで、結構おバカな計算をしていました。しかしながら間違っていても同じアルゴリズムですべての音素が計算されていた結果、MFCC のような何かが生成されており、結果、何となく音素の識別が出来ていたようです(より詳細には、周波数ビンの重み付けの計算にだけ影響が及ぼされていたようなので、比較的似たような何かではあったのかもしれません...)。パワーの計算なども Librosa のものと併せて、同じ値かどうか比較できるように修正しました。以下に流れをまとめておきます。
Jupyter Notebook + Librosa + Matplotlib で検証
Jupyter Notebook を立て、Librosa や関連ライブラリをインストールします。まず Audacity で音声を録音、これを入力として与えてみます。
import librosa import matplotlib.pyplot as plt import numpy as np sample_rate = 16000 n_fft = frame_size n_mels = 40 n_mfcc = 13 y, sr = librosa.core.load('data/o.wav', sr=sample_rate) mfccs_librosa = librosa.feature.mfcc( y=y, sr=sample_rate, n_mels=n_mels, n_fft=n_fft, hop_length=n_fft, n_mfcc=n_mfcc, htk=True) mfccs_librosa = mfccs_librosa.T mfccs_librosa = mfccs_librosa[:,1:] cmin = -40 cmax = 40 plt.clf() im = plt.imshow( mfccs_librosa, cmap='gnuplot', vmin=cmin, vmax=cmax, interpolation='bicubic', aspect=0.2) plt.yticks([]) plt.show()
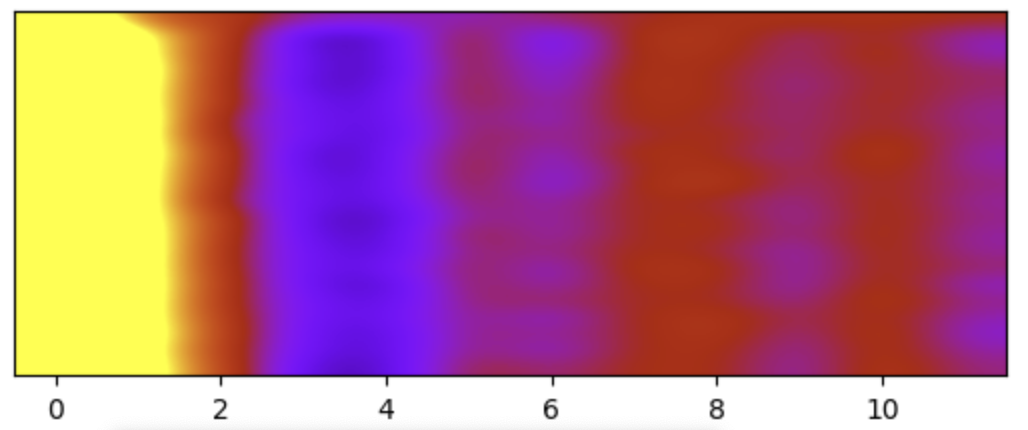
とても簡単に MFCC が得られますね。ではこれを分解して幾つかの部分を自前でコードを書いてみます。
MFCC を Librosa を使わずに計算
base_freq = 1127.010480 def hz_to_mel(freq): return base_freq * np.log10(1.0 + freq / 700.0) def mel_to_hz(mel): return 700.0 * (10.0**(mel / base_freq) - 1.0) # メルフィルタバンク # 後で Burst 向け C# に変換しやすいよう numpy を使わず書いておく def create_mel_filter_bank(num_filters, n_fft, sr): f_max = sr / 2 mel_max = hz_to_mel(f_max) n_max = n_fft // 2 df = float(sr) / n_fft d_mel = mel_max / (num_filters + 1) filters = np.zeros((num_filters, n_max + 1)) for n in range(num_filters): mel_begin = d_mel * n mel_center = d_mel * (n + 1) mel_end = d_mel * (n + 2) f_begin = mel_to_hz(mel_begin) f_center = mel_to_hz(mel_center) f_end = mel_to_hz(mel_end) i_begin = int(math.ceil(f_begin / df)) i_center = int(round(f_center / df)) i_end = int(math.floor(f_end / df)) for i in range(i_begin, i_end): a = 0.0 f = df * i if (i < i_center): a = (f - f_begin) / (f_center - f_begin) else: a = (f_end - f) / (f_end - f_center) a /= (f_end - f_begin) * 0.5 filters[n, i] = a return filters for i in range(num_frames): # 1024 サンプルを取り出す y_frame = y[i * frame_size : (i + 1) * frame_size] # プリエンファシスフィルタ適用 y_preemphasized = np.append(y_frame[0], y_frame[1:] - pre_emphasis * y_frame[:-1]) # 正規化 max_abs_value = np.abs(y_preemphasized).max() y_normalized = y_preemphasized / max_abs_value # ハミング窓適用 window = np.hamming(frame_size) y_windowed = y_normalized * window # FFT y_fft = scipy.fftpack.fft(y_windowed, n_fft) y_fft = np.abs(y_fft) # メルフィルタバンク適用 mel_filter_bank = create_mel_filter_bank(num_mel_filters, n_fft, new_sr) mel_spectrum = np.dot(mel_filter_bank, y_fft[: n_fft // 2 + 1])**2 # log10してパワーを計算してメルスペクトラムを得る log_mel_spectrum = 10 * np.log10(np.abs(mel_spectrum)) # 離散コサイン変換をしてメルケプストラムを得る mfcc = scipy.fftpack.dct(log_mel_spectrum, type=2, norm='ortho') mfcc = mfcc[1:13] mfcc_frames.append(mfcc) plt.clf() im = plt.imshow( mfcc_frames, cmap='gnuplot', vmin=cmin, vmax=cmax, interpolation='bicubic', aspect=0.2) plt.yticks([]) plt.show()
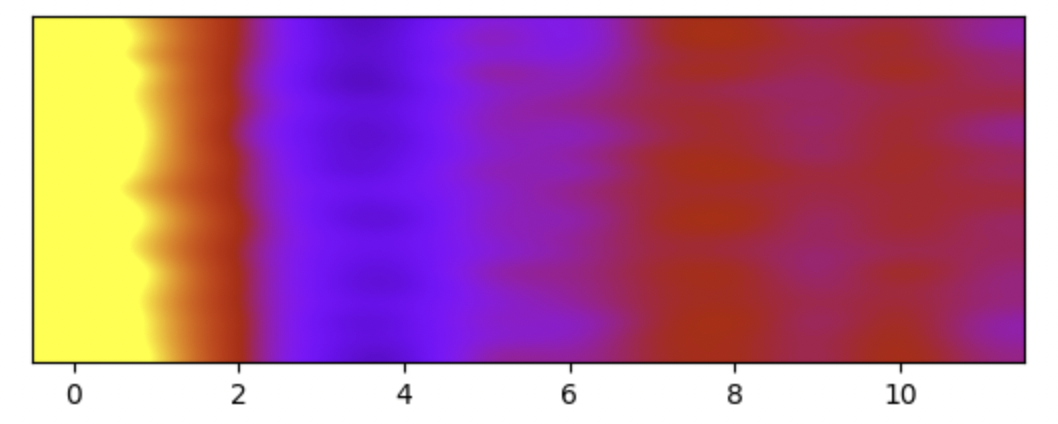
詳細は違いますが概ねスケール感含め同じような MFCC が取得できました。サラッと書いてしまいましたが、この段階でもとのアルゴリズムが間違っていることに気づき、ウンウン唸りながら同じような結果になるように色々と修正をしていました。そしてメルフィルタバンクのミスに気づいた、という形です。
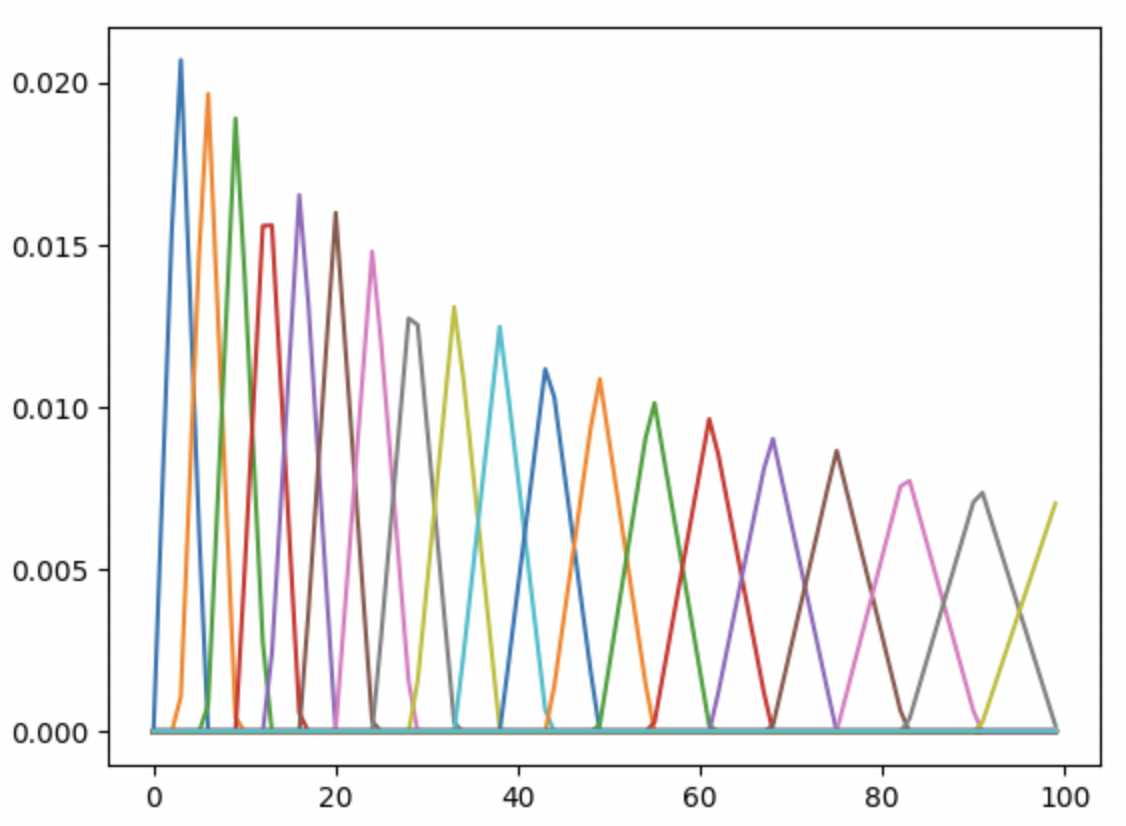
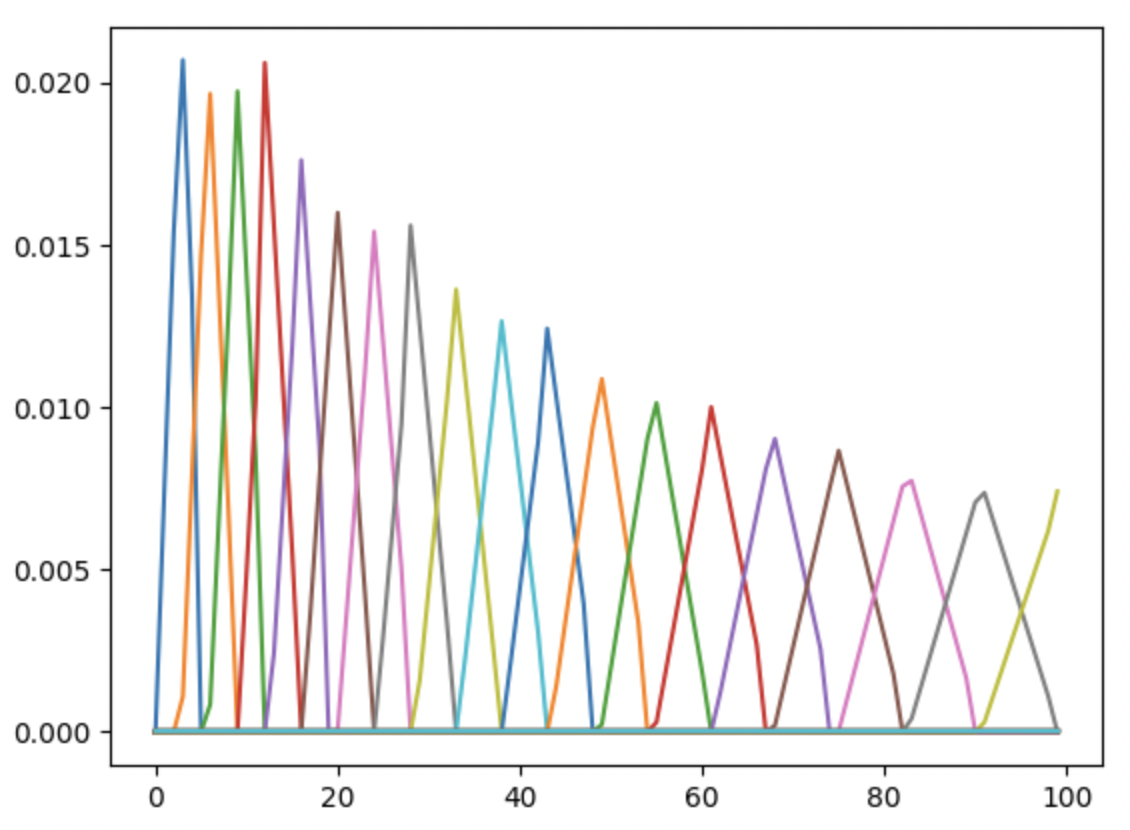
メルフィルタバンクも一応確認してみます。離散的なので細かくは違いますが概ね同じかと...
mel_filter_bank1 = librosa.filters.mel(
sr=sample_rate, n_fft=n_fft, n_mels=n_mels, htk=True)
mel_filter_bank2 = create_mel_filter_bank(
num_mel_filters, n_fft, new_sr)
n = 100
plt.clf()
plt.plot(mel_filter_bank1.T[0:n])
plt.show()
plt.clf()
plt.plot(mel_filter_bank2.T[0:n])
plt.show()
Librosa のメルフィルタバンク
自前のメルフィルタバンク
Unity C# 側への移植
これを C# に移植してみました。
public static void MelFilterBank( in NativeArray<float> spectrum, out NativeArray<float> melSpectrum, float sampleRate, int melDiv) { melSpectrum = new NativeArray<float>(melDiv, Allocator.Temp); MelFilterBank( (float*)spectrum.GetUnsafeReadOnlyPtr(), (float*)melSpectrum.GetUnsafePtr(), spectrum.Length, sampleRate, melDiv); } [BurstCompile] static void MelFilterBank( float* spectrum, float* melSpectrum, int len, float sampleRate, int melDiv) { float fMax = sampleRate / 2; float melMax = ToMel(fMax); int nMax = len / 2; float df = fMax / nMax; float dMel = melMax / (melDiv + 1); for (int n = 0; n < melDiv; ++n) { float melBegin = dMel * n; float melCenter = dMel * (n + 1); float melEnd = dMel * (n + 2); float fBegin = ToHz(melBegin); float fCenter = ToHz(melCenter); float fEnd = ToHz(melEnd); int iBegin = (int)math.ceil(fBegin / df); int iCenter = (int)math.round(fCenter / df); int iEnd = (int)math.floor(fEnd / df); float sum = 0f; for (int i = iBegin + 1; i <= iEnd; ++i) { float f = df * i; float a = (i < iCenter) ? (f - fBegin) / (fCenter - fBegin) : (fEnd - f) / (fEnd - fCenter); a /= (fEnd - fBegin) * 0.5f; sum += a * spectrum[i]; } melSpectrum[n] = sum; } }
これで正しい MFCC が得られているはずです。
Unity での認識結果の出力
さてアルゴリズムは併せましたが本当に計算結果が一致しているかは気になるところです。そこで、Unity での計算結果を CSV に書き出して Jupyter Notebook で描画してみて、Librosa の出力と一致しているかを見てみることにします。ただ CSV の出力はユーザーは必要ないので、開発時のみこの機能が ON になるように、デバッグフラグを ON にしたときのみ幾つかのコードが追加され、少しのオーバーヘッドを犠牲に途中の計算結果などを出力できるようにしてみました。
まず、Project Settings > Player から Scripting Define Symbols に ULIPSYNC_DEBUG というフラグを追加します。
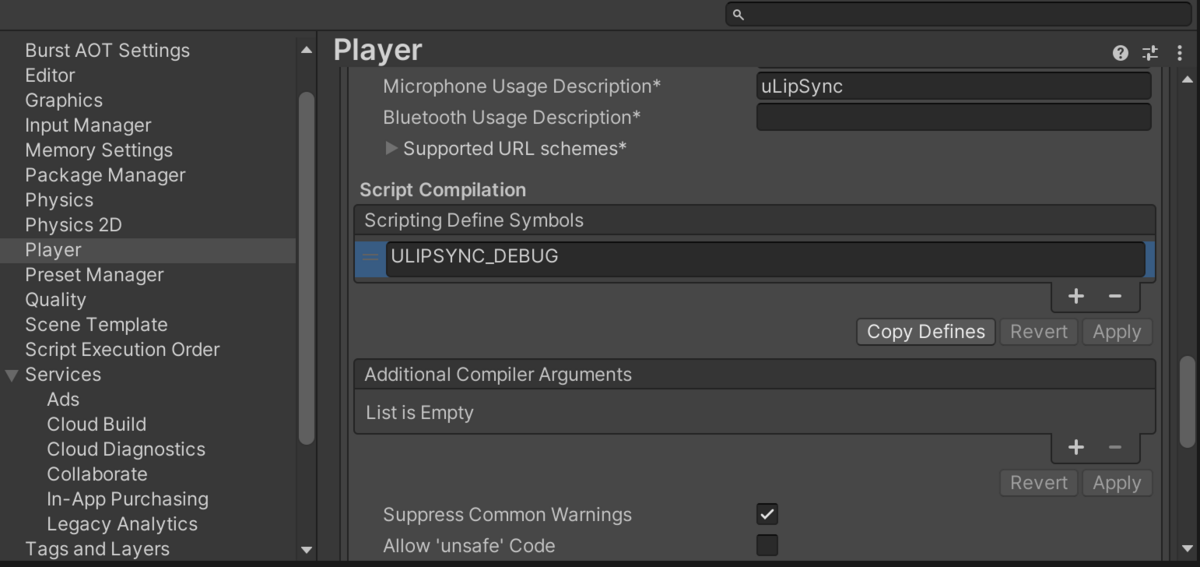
ちょっと面倒ですが、このフラグが立っているときにバッファを追加し、ジョブ側で計算の途中結果をコピーするようにしました。以下に関連している付近のコードのみ抜粋します。
uLipSync.cs
public class uLipSync : MonoBehaviour { ... #if ULIPSYNC_DEBUG NativeArray<float> _debugData; NativeArray<float> _debugSpectrum; NativeArray<float> _debugMelSpectrum; NativeArray<float> _debugMelCepstrum; NativeArray<float> _debugDataForOther; NativeArray<float> _debugSpectrumForOther; NativeArray<float> _debugMelSpectrumForOther; NativeArray<float> _debugMelCepstrumForOther; public NativeArray<float> data => _debugDataForOther; public NativeArray<float> spectrum => _debugSpectrumForOther; public NativeArray<float> melSpectrum => _debugMelSpectrumForOther; public NativeArray<float> melCepstrum => _debugMelCepstrumForOther; #endif ... ... void UpdateResult() { _jobHandle.Complete(); _mfccForOther.CopyFrom(_mfcc); #if ULIPSYNC_DEBUG _debugDataForOther.CopyFrom(_debugData); _debugSpectrumForOther.CopyFrom(_debugSpectrum); _debugMelSpectrumForOther.CopyFrom(_debugMelSpectrum); _debugMelCepstrumForOther.CopyFrom(_debugMelCepstrum); #endif ... } ... void ScheduleJob() { ... var lipSyncJob = new LipSyncJob() { ... #if ULIPSYNC_DEBUG debugData = _debugData, debugSpectrum = _debugSpectrum, debugMelSpectrum = _debugMelSpectrum, debugMelCepstrum = _debugMelCepstrum, #endif }; _jobHandle = lipSyncJob.Schedule(); } }
LipSyncJob.cs
[BurstCompile] public struct LipSyncJob : IJob { ... #if ULIPSYNC_DEBUG public NativeArray<float> debugData; public NativeArray<float> debugSpectrum; public NativeArray<float> debugMelSpectrum; public NativeArray<float> debugMelCepstrum; #endif public void Execute() { Algorithm.CopyRingBuffer(input, out var buffer, startIndex); Algorithm.LowPassFilter(ref buffer, outputSampleRate, cutoff, range); Algorithm.DownSample(buffer, out var data, outputSampleRate, targetSampleRate); Algorithm.PreEmphasis(ref data, 0.97f); Algorithm.HammingWindow(ref data); Algorithm.Normalize(ref data, 1f); Algorithm.ZeroPadding(ref data, out dataWithZeroPadding); Algorithm.FFT(dataWithZeroPadding, out var spectrum); Algorithm.MelFilterBank(spectrum, out var melSpectrum, targetSampleRate, melFilterBankChannels); for (int i = 0; i < melSpectrum.Length; ++i) { melSpectrum[i] = 10f * math.log10(melSpectrum[i]); } Algorithm.DCT(melSpectrum, out var melCepstrum); ... #if ULIPSYNC_DEBUG dataWithZeroPadding.CopyTo(debugData); spectrum.CopyTo(debugSpectrum); melSpectrum.CopyTo(debugMelSpectrum); melCepstrum.CopyTo(debugMelCepstrum); #endif ... } }
これで NativeArray<float> で色々な計算結果を外部から取得できるようになりました。そしてこれをファイルに書き出すデバッグ用のコンポーネントを追加します。
[RequireComponent(typeof(uLipSync))] public class DebugDump : MonoBehaviour { public uLipSync lipsync { get; private set; } public string prefix = ""; public string dataFile = "data.csv"; public string spectrumFile = "spectrum.csv"; public string melSpectrumFile = "mel-spectrum.csv"; public string melCepstrumFile = "mel-cepstrum.csv"; public string mfccFile = "mfcc.csv"; void Start() { lipsync = GetComponent<uLipSync>(); } public void DumpAll() { DumpData(); DumpSpectrum(); DumpMelSpectrum(); DumpMelCepstrum(); DumpMfcc(); } public void DumpData() { #if ULIPSYNC_DEBUG if (string.IsNullOrEmpty(dataFile)) return; var fileName = $"{prefix}{dataFile}"; var sw = new StreamWriter(fileName); var data = lipsync.data; var dt = 1f / (lipsync.profile.targetSampleRate * 2); for (int i = 0; i < data.Length; ++i) { var t = dt * i; var val = data[i]; sw.WriteLine($"{t},{val}"); } sw.Close(); Debug.Log($"{fileName} was created."); #endif } public void DumpSpectrum() { #if ULIPSYNC_DEBUG if (string.IsNullOrEmpty(spectrumFile)) return; var fileName = $"{prefix}{spectrumFile}"; var sw = new StreamWriter(fileName); var spectrum = lipsync.spectrum; var df = (float)lipsync.profile.targetSampleRate / spectrum.Length; for (int i = 0; i < spectrum.Length; ++i) { var f = df * i; var val = math.log(spectrum[i]); sw.WriteLine($"{f},{val}"); } sw.Close(); Debug.Log($"{fileName} was created."); #endif } public void DumpMelSpectrum() { #if ULIPSYNC_DEBUG ... #endif } public void DumpMelCepstrum() { #if ULIPSYNC_DEBUG ... #endif } public void DumpMfcc() { #if ULIPSYNC_DEBUG ... #endif } }
数値を CSV に書き出すだけのシンプルなスクリプトです。あとはエディタ拡張も書いてこれらを一括 / 個別で簡単にファイルに出力できるようにしておきます。
また、同様に Profile や uLipSync のエディタ拡張にも ULIPSYNC_DEBUG が立っている時だけ追加される MFCC 出力のデバッグを追加しておきます。これによって、プロファイルに登録されている MFCC や現在の数フレームの間に認識された MFCC をダンプすることが出来るようになります。たとえば uLipSync のエディタ拡張はこんな感じです。
uLipSyncEditor.cs
[CustomEditor(typeof(uLipSync))] public class uLipSyncEditor : Editor { ... public override void OnInspectorGUI() { ... if (EditorUtil.Foldout("Runtime Information", false)) { ... if (Application.isPlaying) { DrawCurrentMfcc(); } ... } ... } void DrawCurrentMfcc() { ... #if ULIPSYNC_DEBUG EditorGUILayout.BeginHorizontal(); GUILayout.FlexibleSpace(); if (GUILayout.Button("Dump")) { var date = System.DateTime.Now; var filename = $"{date:yyyyMMddHHmmss}.csv"; var sw = new StreamWriter(filename); var sb = new StringBuilder(); Debugging.DebugUtil.DumpMfccData(sb, _mfccData); sw.Write(sb); sw.Close(); Debug.Log($"{filename} was created."); } EditorGUILayout.EndHorizontal(); #endif } ... }
これで次のようにエディタ拡張にボタンが追加されます。


再度 Jupyter Notebook に戻って検証
先ほど追加した仕組みを使って Profile を CSV を出力し、Python 側で読み取って見てみます。
import matplotlib.pyplot as plt import pandas as pd def draw(df, aspect, cmin=cmin, cmax=cmax): plt.clf() im = plt.imshow( df, cmap='gnuplot', vmin=cmin, vmax=cmax, interpolation='bicubic', aspect=aspect) plt.yticks([]) plt.xticks([]) plt.tight_layout(pad=0, h_pad=0.01, w_pad=0) plt.show() for phoneme in ['A', 'I', 'U', 'E', 'O']: path = f'data/DebugProfile-{phoneme}.csv' df = pd.read_csv(path, header=None) draw(df, 0.05, -40, 40)
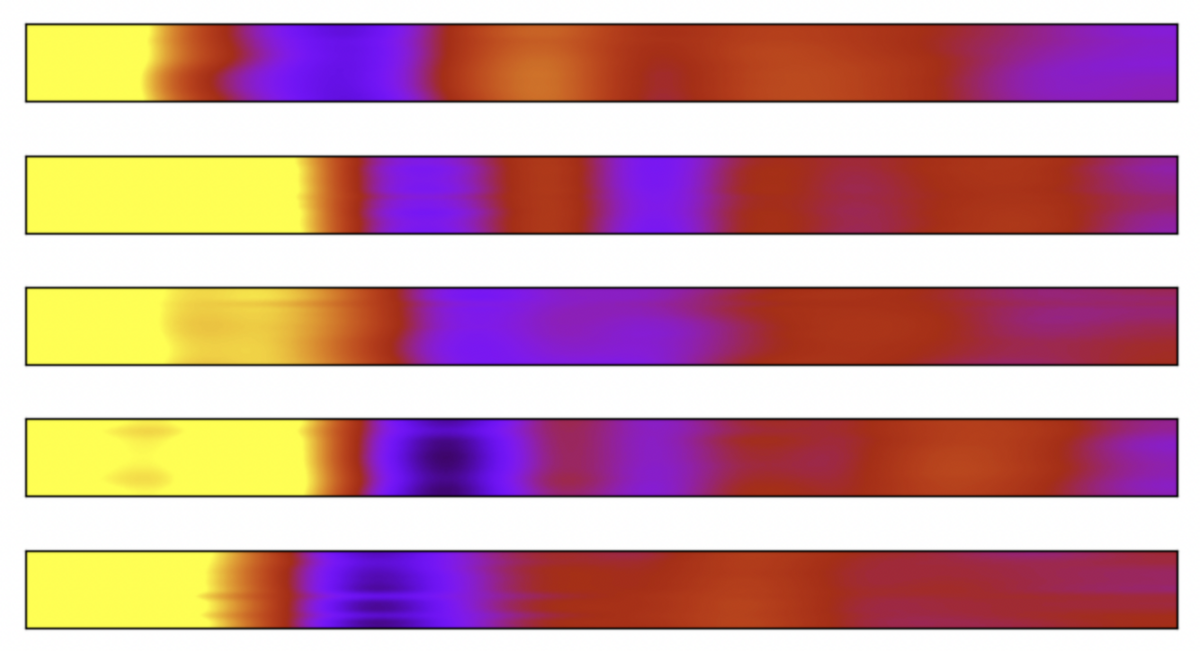
最初に Librosa で見たものと似たような値が得られていることがわかります!uLipSync の Dump 機能を使って、もう少し長いデータで同じ「O」の音素を見てみます。
df = pd.read_csv('data/20230331012825.csv', header=None) draw(df, 0.05)

概ね良さそうな感じがします。ぴったりと Librosa に併せることが目的ではなく、あくまで MFCC を得ることで音素比較が出来るようにすることが目的なので、これで要件は満たせそうです。
検証の過程では、こうして得られた MFCC 比較を行う上で、どういった比較関数が良さそうかの検証も行ってみました(L1ノルム、L2ノルム、コサイン類似度、および MFCC の各係数を標準化した場合 / しない場合など)。検証した感じだと、コサイン類似度(標準化なし)が最終的に得られるスコアも 0 ~ 1 であり良さそうな感じでした。下記は、事前にはっきり発音して取得しておいた「あいうえお」の MFCC と、別の感じで発音した「あいうえお」のデータを比較したときのスコア(コサイン類似度 = 内積)です。
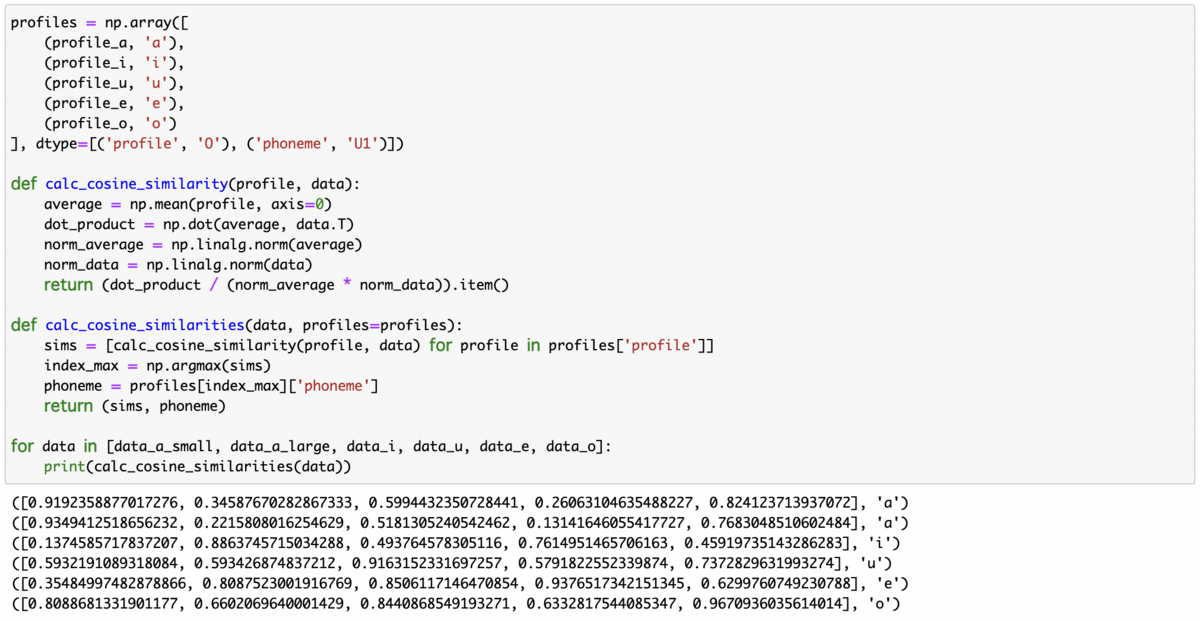
ユースケースにもよるかもしれないので、ひとまずこれらは Profile で選択できるオプションとした上でユーザが選択できる形にしておこうかなと思います。
おわりに
今月末リリースを目標にしていたのですが、思っていたよりも時間がかかってしまったので、来月リリースします。今回は触れませんでしたが、他にも色々とアップデートがありますので、併せて色々紹介できればと思います。
また、今回検証するに当たり、ChatGPT Model:GPT-4 のお世話になりました。特に Python 周りと音声信号処理周りの知識の学習についはこれ無しでは 10 倍くらい進みが違っただろうな、と思うくらい新しい学習及びコーディングの体験でした。今後もライセンス周りなどは気にしつつ、うまく活用していきたいです。